前端小册
道虽迩,行则将至
Vinsiny 前端小册是一个整理记录前端知识的仓库,利用mdbook搭建gh-pages在线阅读,可在线阅读,也可查看文档源库
使用下面命令,用于通过 HTTP 在 localhost:3000 提供本地预览服务:
mdbook serve
TODO
- 浏览器同源策略的起因、限制、解决方案
浏览器performance 内存优化、long task 优化;- 隐士类型转换
- 函数式编程、面向对象编程
- 依赖注入、依赖反转
ts: type 和 interface 区别- lazy 加载实现原理
- useState/useReducer 状态保存原理
https 安全保证,ca 公钥- errorboundry 捕获哪些错误?
css 选择器和优先级vue2 双向绑定- csp
- new Objet() 和 Object.create()
- monorepo 概念
- 关于项目的深入理解
- webpack plugin/loader 实现?看一到两个pluin源码
收藏
- 一文读懂跨平台技术的前世今生
- 一文了解 NextJS 并对性能优化做出最佳实践
- 一起来做类型体操
- 如何参与大型开源项目-Taro 共建
- zoo team
- Redux状态管理之痛点、分析与改良
- 我看Next.js:一个更现代的海王
- Nodejs技术栈
- github/JavaScript-Note
gh-pages 发布 github acitons 配置
- 自动发布 gh-pages aciton 配置: https://github.com/rust-lang/mdBook/wiki/Automated-Deployment:-GitHub-Actions
React 、mobx 、redux…
setState被调用之后,更新组件的过程,下面是一个简单的流程图。
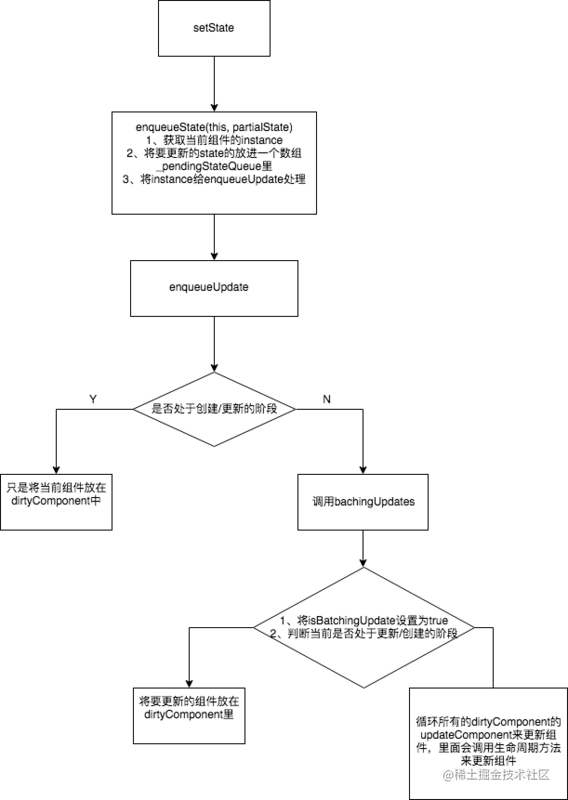
下面来逐步的解析图里的流程。
一、setState
ReactBaseClassses.js
ReactComponent.prototype.setState = function (partialState, callback) {
// 将setState事务放进队列中
this.updater.enqueueSetState(this, partialState);
if (callback) {
this.updater.enqueueCallback(this, callback, 'setState');
}
};
这里的partialState可以传object,也可以传function,它会产生新的state以一种Object.assgine()的方式跟旧的state进行合并。
二、enqueueSetState
enqueueSetState: function (publicInstance, partialState) {
// 获取当前组件的instance
var internalInstance = getInternalInstanceReadyForUpdate(publicInstance, 'setState');
// 将要更新的state放入一个数组里
var queue = internalInstance._pendingStateQueue || (internalInstance._pendingStateQueue = []);
queue.push(partialState);
// 将要更新的component instance也放在一个队列里
enqueueUpdate(internalInstance);
}
这段代码可以得知,enqueueSetState 做了两件事:
- 将新的
state放进数组里 - 用
enqueueUpdate来处理将要更新的实例对象
三、enqueueUpdate
ReactUpdates.js
function enqueueUpdate(component) {
// 如果没有处于批量创建/更新组件的阶段,则处理update state事务
if (!batchingStrategy.isBatchingUpdates) {
batchingStrategy.batchedUpdates(enqueueUpdate, component);
return;
}
// 如果正处于批量创建/更新组件的过程,将当前的组件放在dirtyComponents数组中
dirtyComponents.push(component);
}
由这段代码可以看到,当前如果正处于创建/更新组件的过程,就不会立刻去更新组件,而是先把当前的组件放在dirtyComponent里,所以不是每一次的setState都会更新组件~。
这段代码就解释了我们常常听说的:setState是一个异步的过程,它会集齐一批需要更新的组件然后一起更新。
而 batchingStrategy 又是个什么东西呢?
四、batchingStrategy
ReactDefaultBatchingStrategy.js
var ReactDefaultBatchingStrategy = {
// 用于标记当前是否出于批量更新
isBatchingUpdates: false,
// 当调用这个方法时,正式开始批量更新
batchedUpdates: function (callback, a, b, c, d, e) {
var alreadyBatchingUpdates = ReactDefaultBatchingStrategy.isBatchingUpdates;
ReactDefaultBatchingStrategy.isBatchingUpdates = true;
// 如果当前事务正在更新过程在中,则调用callback,既enqueueUpdate
if (alreadyBatchingUpdates) {
return callback(a, b, c, d, e);
} else {
// 否则执行更新事务
return transaction.perform(callback, null, a, b, c, d, e);
}
}
};
这里注意两点:
- 如果当前事务正在更新过程中,则使用
enqueueUpdate将当前组件放在dirtyComponent里。 - 如果当前不在更新过程的话,则执行更新事务。
五、transaction
/**
* <pre>
* wrappers (injected at creation time)
* + +
* | |
* +-----------------|--------|--------------+
* | v | |
* | +---------------+ | |
* | +--| wrapper1 |---|----+ |
* | | +---------------+ v | |
* | | +-------------+ | |
* | | +----| wrapper2 |--------+ |
* | | | +-------------+ | | |
* | | | | | |
* | v v v v | wrapper
* | +---+ +---+ +---------+ +---+ +---+ | invariants
* perform(anyMethod) | | | | | | | | | | | | maintained
* +----------------->|-|---|-|---|-->|anyMethod|---|---|-|---|-|-------->
* | | | | | | | | | | | |
* | | | | | | | | | | | |
* | | | | | | | | | | | |
* | +---+ +---+ +---------+ +---+ +---+ |
* | initialize close |
* +-----------------------------------------+
* </pre>
*/
简单说明一下transaction对象,它暴露了一个perform的方法,用来执行anyMethod,在anyMethod执行的前,需要先执行所有wrapper的initialize方法,在执行完后,要执行所有wrapper的close方法,就辣么简单。
在ReactDefaultBatchingStrategy.js,tranction 的 wrapper有两个 FLUSH_BATCHED_UPDATES, RESET_BATCHED_UPDATES
var RESET_BATCHED_UPDATES = {
initialize: emptyFunction,
close: function () {
ReactDefaultBatchingStrategy.isBatchingUpdates = false;
}
};
var FLUSH_BATCHED_UPDATES = {
initialize: emptyFunction,
close: ReactUpdates.flushBatchedUpdates.bind(ReactUpdates)
};
var TRANSACTION_WRAPPERS = [FLUSH_BATCHED_UPDATES, RESET_BATCHED_UPDATES];
可以看到,这两个wrapper的initialize都没有做什么事情,但是在callback执行完之后,RESET_BATCHED_UPDATES 的作用是将isBatchingUpdates置为false, FLUSH_BATCHED_UPDATES 的作用是执行flushBatchedUpdates,然后里面会循环所有dirtyComponent,调用updateComponent来执行所有的生命周期方法,componentWillReceiveProps, shouldComponentUpdate, componentWillUpdate, render, componentDidUpdate 最后实现组件的更新。以上即为setState的实现过程,最后还是用一个流程图在做一个总结吧~
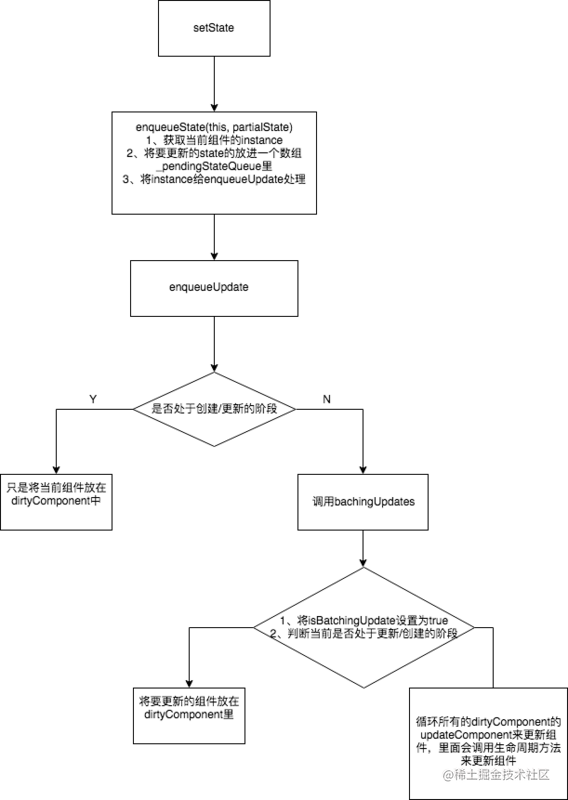
setState的流程
渲染的入口是 preformSyncWorkOnRoot 函数,setState 修改完状态后,触发这个函数即可。
setState 会调用 dispatchAction , 创建一个 update 对象放到 fiber 节点的 updateQueue 上,然后调度渲染。
react 会先触发 update 的 fiber 往上找到 根fiber 节点,然后再调用 performSyncWorkOnRoot 的函数进行渲染
而 setState 是同步还是异步,也就是在这一段控制的。
在scheduleUpdateOnFilber更新函数中,有个判断条件里有个 excutionContext , 这个是用来标识当前环境的,比如是批量还是非批量,是否执行过 render 阶段,commit 阶段
在 ReactDom.render 执行的时候会先调用 unBatchUpdate 函数,这个函数会在 excutionContext 中设置一个 unbatch 的 flag, 这样在 update 的时候,就会立刻执行 preformSyncWorkOnRoot 来渲染,因为首次渲染的时候是要马上渲染的,没必要调度。
之后走到 commit 阶段会设置一个 commit 的 flag
然后再次 setState 就不会走到 unbatch 的分支了。
为什么 setTimeout 里面的 setState 会 同步执行呢?
因为直接从 setTimeout 执行的异步代码是没有设置 excutionContext 的, 那就会走到 NoContext 的分支,会立刻渲染。
参考链接: https://juejin.cn/post/7113535510894608414
使用 JavaScript Proxy 实现简单的数据绑定
<body>
hello,world
<input type="text" id="model">
<p id="word"></p>
</body>
<script>
const model = document.getElementById("model")
const word = document.getElementById("word")
var obj= {};
const newObj = new Proxy(obj, {
get: function(target, key, receiver) {
console.log(`getting ${key}!`);
return Reflect.get(target, key, receiver);
},
set: function(target, key, value, receiver) {
console.log('setting',target, key, value, receiver);
if (key === "text") {
model.value = value;
word.innerHTML = value;
}
return Reflect.set(target, key, value, receiver);
}
});
model.addEventListener("keyup",function(e){
newObj.text = e.target.value
})
</script>
参考文章:
1. 模块历史
amd(async module definition)、cmd(common module definition) 社区提供的 js 模块语言规范(逐渐淘汰); commonjs => nodejs的内置模块 esmodule => js/es 的语言模块规范
2. es module
大部分浏览器支持 es module,成为事实上 js 模块规范
2.1 module script 标签注意点
- script 标签使用时,方式如下:
<script type="module">
var str = 'hello';
</script>
- 模块内默认是严格模式;
- 模块内变量是单独作用域,其他模块无法直接使用;
type=module标签的script脚本默认带有defer属性,即延迟执行,不阻塞 html 结构解析,加载完成后执行对应脚本;- esm 通过 cors 方式请求的,需要server 端支持cors;
// baidu cdn 不支持跨域请求,会报跨域错误
<script type="module" src="https://libs.baidu.com/jquery/2.0.0/jquery.min.js"></script>
// unpkg 支持cors,可以正常下载
<script type="module" src="https://unpkg.com/jquery@3.4.1/dist/jquery.min.js"></script>
2.2 esm 导入导出注意点
- 导入的是变量的应用
// module.js
export var foo ='hello';
setTimeout(function() {
foo = 'world';
}, 1000);
// app.js
import { foo } from './module.js';
console.log(foo); // hello
setTimeout(function() {
console.log(foo); // world
}, 1000);
- 导入的成员是不可变变量,即约等于声明了
const foo
// module.js
export var foo ='hello';
// app.js
import { foo } from './module.js';
console.log(foo); // hello
foo = 'world'; // error
export { xx, xxx }是一种esm 语法,不等于对象结构语法
// module.js
var foo ='hello';
var bar = 'bar str';
export { bar, foo }; // 默认语法
var obj = {
foo, bar
}
export obj; // 导出 obj 对象,两者不同
type 和 interface 的区别
官方文档对二者的说明:
- An interface can be named in an extends or implements clause, but a type alias for an object type literal cannot.
- An interface can have multiple merged declarations, but a type alias for an object type literal cannot.
相同点
- 都可以描述一个对象或者函数;
- 都允许拓展(extends),两者语法存在一定差异
// base interface
interface IName {
name: string;
}
// base type
type TName = = {
name: string;
}
// interface extends interface
interface IUser extends IName {
age: number;
}
// type extends type
type TUser = TName & { age: number };
// interface extends type
interface IUser extends TName {
age: number;
}
// type extends interface
type TUser = IName & {
age: number;
}
不同点
1. type 可以而 interface 不行
- type 可以声明基本类型别名、联合类型、元组等类型;
// 1. 基本类型别名
type Name = string
// 2. 联合类型
interface Dog {
wong();
}
interface Cat {
miao();
}
type Pet = Dog | Cat
// 3. 具体定义数组每个位置的类型,元组
type PetList = [Dog, Pet]
- type 语句中还可以使用
typeof获取实例的类型进行赋值
// 当你想获取一个变量的类型时,使用 typeof
let div = document.createElement('div');
type B = typeof div
2. interface 可以而 type 不行
- interface 能够声明合并
interface User {
name: string
age: number
}
interface User {
sex: string
}
/*
User 接口为 {
name: string
age: number
sex: string
}
*/
总结
一般来说,如果不清楚什么时候用interface/type,能用 interface 实现,就用 interface , 如果不能就用 type;
unknow 和 any 的区别
any
- 任何类型都可以被归为 any 类型,any 是顶级类型(也被称作全局超级类型);
- any 类型本质上是类型系统的一个逃逸舱,TypeScript 允许我们对 any 类型的值执行任何操作,而无需事先执行任何形式的检查;
unknow
- 所有类型也都可以赋值给 unknown;
- unknown 类型只能被赋值给 any 类型和 unknown 类型本身(这是有道理的:只有能够保存任意类型值的容器才能保存 unknown 类型的值。毕竟我们不知道变量 value 中存储了什么类型的值);
- 将 value 变量类型设置为 unknown 后,这些操作都不再被认为是类型正确的。通过将 any 类型改变为 unknown 类型,我们已将允许所有更改的默认设置,更改为禁止任何更改。
let value: unknown;
value.foo.bar; // Error
value.trim(); // Error
value(); // Error
new value(); // Error
value[0][1]; // Error
TS 类型体操
1. 有哪些类型
类型体操的主要类型列举在图中。Typescript 复用了 JS 的基础类型和复合类型,并新增元组(Tuple)、接口(Interface)、枚举(Enum)等类型,这些类型在日常开发过程中类型声明应该都很常用,不做赘述。

2. 运算逻辑
TypeScript 支持条件、推导、联合、交叉、对联合类型做映射等 9 种运算逻辑。

- 条件:T extends U ? X : Y
条件判断和 js 逻辑相同,都是如果满足条件就返回 a 否则返回 b。
// 条件:extends ? :
// 如果 T 是 2 的子类型,那么类型是 true,否则类型是 false。
type isTwo<T> = T extends 2 ? true : false;
// false
type res = isTwo<1>;
- 约束:extends
通过约束语法 extends 限制类型。
// 通过 T extends Length 约束了 T 的类型,必须是包含 length 属性,且 length 的类型必须是 number。
interface Length {
length: number
}
function fn1<T extends Length>(arg: T): number{
return arg.length
}
- 推导:infer
推导则是类似 js 的正则匹配,都满足公式条件时,可以提取公式中的变量,直接返回或者再次加工都可以。
// 推导:infer
// 提取元组类型的第一个元素:
// extends 约束类型参数只能是数组类型,因为不知道数组元素的具体类型,所以用 unknown。
// extends 判断类型参数 T 是不是 [infer F, ...infer R] 的子类型,如果是就返回 F 变量,如果不是就不返回
type First<T extends unknown[]> = T extends [infer F, ...infer R] ? F : never;
// 1
type res2 = First<[1, 2, 3]>;
- 联合:|
联合代表可以是几个类型之一。
type Union = 1 | 2 | 3
- 交叉:&
交叉代表对类型做合并。
type ObjType = { a: number } & { c: boolean }
- 索引查询:keyof T
keyof 用于获取某种类型的所有键,其返回值是联合类型。
// const a: 'name' | 'age' = 'name'
const a: keyof {
name: string,
age: number
} = 'name'
- 索引访问:T[K]
T[K] 用于访问索引,得到索引对应的值的联合类型。
interface I3 {
name: string,
age: number
}
type T6 = I3[keyof I3] // string | number
- 索引遍历: in
in 用于遍历联合类型。
const obj = {
name: 'tj',
age: 11
}
type T5 = {
[P in keyof typeof obj]: any
}
/*
{
name: any,
age: any
}
*/
- 索引重映射: as as 用于修改映射类型的 key。
// 通过索引查询 keyof,索引访问 t[k],索引遍历 in,索引重映射 as,返回全新的 key、value 构成的新的映射类型
type MapType<T> = {
[
Key in keyof T
as `${Key & string}${Key & string}${Key & string}`
]: [T[Key], T[Key], T[Key]]
}
// {
// aaa: [1, 1, 1];
// bbb: [2, 2, 2];
// }
type res3 = MapType<{ a: 1, b: 2 }>
3. 运算套路
根据上面介绍的 9 种运算逻辑,我总结了 4 个类型套路。
- 模式匹配做提取;
- 重新构造做变换;
- 递归复用做循环;
- 数组长度做计数。
3.1 模式匹配做提取
第一个类型套路是模式匹配做提取。
模式匹配做提取的意思是通过类型 extends 一个模式类型,把需要提取的部分放到通过 infer 声明的局部变量里。
举个例子,用模式匹配提取函数参数类型。
type GetParameters<Func extends Function> =
Func extends (...args: infer Args) => unknown ? Args : never;
type ParametersResult = GetParameters<(name: string, age: number) => string>
首先用 extends 限制类型参数必须是 Function 类型。
然后用 extends 为 参数类型匹配公式,当满足公式时,提取公式中的变量 Args。
实现函数参数类型的提取。
3.2 重新构造做变换
第二个类型套路是重新构造做变换。
重新构造做变换的意思是想要变化就需要重新构造新的类型,并且可以在构造新类型的过程中对原类型做一些过滤和变换。
比如实现一个字符串类型的重新构造。
type CapitalizeStr<Str extends string> =
Str extends `${infer First}${infer Rest}`
? `${Uppercase<First>}${Rest}` : Str;
type CapitalizeResult = CapitalizeStr<'tang'>
首先限制参数类型必须是字符串类型。
然后用 extends 为参数类型匹配公式,提取公式中的变量 First Rest,并通过 Uppercase 封装。
实现了首字母大写的字符串字面量类型。

3.3 递归复用做循环
第三个类型套路是递归复用做循环。
Typescript 本身不支持循环,但是可以通过递归完成不确定数量的类型编程,达到循环的效果。
比如通过递归实现数组类型反转。
type ReverseArr<Arr extends unknown[]> =
Arr extends [infer First, ...infer Rest]
? [...ReverseArr<Rest>, First]
: Arr;
type ReverseArrResult = ReverseArr<[1, 2, 3, 4, 5]>
首先限制参数必须是数组类型。
然后用 extends 匹配公式,如果满足条件,则调用自身,否则直接返回。
实现了一个数组反转类型。
3.4 数组长度做计数
第四个类型套路是数组长度做计数。
类型编程本身是不支持做加减乘除运算的,但是可以通过递归构造指定长度的数组,然后取数组长度的方式来完成数值的加减乘除。
比如通过数组长度实现类型编程的加法运算。
type BuildArray<
Length extends number,
Ele = unknown,
Arr extends unknown[] = []
> = Arr['length'] extends Length
? Arr
: BuildArray<Length, Ele, [...Arr, Ele]>;
type Add<Num1 extends number, Num2 extends number> =
[...BuildArray<Num1>, ...BuildArray<Num2>]['length'];
type AddResult = Add<32, 25>
首先通过递归创建一个可以生成任意长度的数组类型
然后创建一个加法类型,通过数组的长度来实现加法运算。

三、类型体操实践
分享的第三部分是类型体操实践。
前面分享了类型体操的概念及常用的运算逻辑。
下面我们就用这些运算逻辑来解析 Typescript 内置的高级类型。
- 解析 Typescript 内置高级类型
- Partial 把索引变为可选
通过 in 操作符遍历索引,为所有索引添加 ?前缀实现把索引变为可选的新的映射类型。
type TPartial<T> = {
[P in keyof T]?: T[P];
};
type PartialRes = TPartial<{ name: 'aa', age: 18 }>
- Required 把索引变为必选
通过 in 操作符遍历索引,为所有索引删除 ?前缀实现把索引变为必选的新的映射类型。
type TRequired<T> = {
[P in keyof T]-?: T[P]
}
type RequiredRes = TRequired<{ name?: 'aa', age?: 18 }>
- Readonly 把索引变为只读
通过 in 操作符遍历索引,为所有索引添加 readonly 前缀实现把索引变为只读的新的映射类型。
type TReadonly<T> = {
readonly [P in keyof T]: T[P]
}
type ReadonlyRes = TReadonly<{ name?: 'aa', age?: 18 }>
- Pick 保留过滤索引
首先限制第二个参数必须是对象的 key 值,然后通过 in 操作符遍历第二个参数,生成新的映射类型实现。
type TPick<T, K extends keyof T> = {
[P in K]: T[P]
}
type PickRes = TPick<{ name?: 'aa', age?: 18 }, 'name'>
- Record 创建映射类型
通过 in 操作符遍历联合类型 K,创建新的映射类型。
type TRecord<K extends keyof any, T> = {
[P in K]: T
}
type RecordRes = TRecord<'aa' | 'bb', string>
- Exclude 删除联合类型的一部分
通过 extends 操作符,判断参数 1 能否赋值给参数 2,如果可以则返回 never,以此删除联合类型的一部分。
type TExclude<T, U> = T extends U ? never : T
type ExcludeRes = TExclude<'aa' | 'bb', 'aa'>
- Extract 保留联合类型的一部分
和 Exclude 逻辑相反,判断参数 1 能否赋值给参数 2,如果不可以则返回 never,以此保留联合类型的一部分。
type TExtract<T, U> = T extends U ? T : never
type ExtractRes = TExtract<'aa' | 'bb', 'aa'>
- Omit 删除过滤索引
通过高级类型 Pick、Exclude 组合,删除过滤索引。
type TOmit<T, K extends keyof T> = Pick<T, Exclude<keyof T, K>>
type OmitRes = TOmit<{ name: 'aa', age: 18 }, 'name'>
- Awaited 用于获取 Promise 的 valueType
通过递归来获取未知层级的 Promise 的 value 类型。
type TAwaited<T> =
T extends null | undefined
? T
: T extends object & { then(onfulfilled: infer F): any }
? F extends ((value: infer V, ...args: any) => any)
? Awaited<V>
: never
: T;
type AwaitedRes = TAwaited<Promise<Promise<Promise<string>>>>
还有非常多高级类型,实现思路和上面介绍的类型套路大多一致,这里不一一赘述。
- 解析 ParseQueryString 复杂类型 重点解析的是在背景章节介绍类型体操复杂度,举例说明的解析字符串参数的函数类型。
如图示 demo 所示,这个函数是用于将指定字符串格式解析为对象格式。
function parseQueryString1(queryStr) {
if (!queryStr || !queryStr.length) {
return {}
}
const queryObj = {}
const items = queryStr.split('&')
items.forEach((item) => {
const [key, value] = item.split('=')
if (queryObj[key]) {
if (Array.isArray(queryObj[key])) {
queryObj[key].push(value)
} else {
queryObj[key] = [queryObj[key], value]
}
} else {
queryObj[key] = value
}
})
return queryObj
}
比如获取字符串 a=1&b=2 中 a 的值。
常用的类型声明方式如下图所示:
function parseQueryString1(queryStr: string): Record<string, any> {
if (!queryStr || !queryStr.length) {
return {}
}
const queryObj = {}
const items = queryStr.split('&')
items.forEach((item) => {
const [key, value] = item.split('=')
if (queryObj[key]) {
if (Array.isArray(queryObj[key])) {
queryObj[key].push(value)
} else {
queryObj[key] = [queryObj[key], value]
}
} else {
queryObj[key] = value
}
})
return queryObj
}
参数类型为 string,返回类型为 Record<string, any>,这时看到,res1.a 类型为 any,那么有没有办法,准确的知道 a 的类型是字面量类型 1 呢?
下面就通过类型体操的方式,来重写解析字符串参数的函数类型。
type ParseParam<Param extends string> =
Param extends `${infer Key}=${infer Value}`
? {
[K in Key]: Value
} : Record<string, any>;
type MergeParams<
OneParam extends Record<string, any>,
OtherParam extends Record<string, any>
> = {
readonly [Key in keyof OneParam | keyof OtherParam]:
Key extends keyof OneParam
? OneParam[Key]
: Key extends keyof OtherParam
? OtherParam[Key]
: never
}
type ParseQueryString<Str extends string> =
Str extends `${infer Param}&${infer Rest}`
? MergeParams<ParseParam<Param>, ParseQueryString<Rest>>
: ParseParam<Str>;
首先限制参数类型是 string 类型,然后为参数匹配公式 a&b,如果满足公式,将 a 解析为 key value 的映射类型,将 b 递归 ParseQueryString 类型,继续解析,直到不再满足 a&b 公式。
最后,就可以得到一个精准的函数返回类型,res.a = 1。
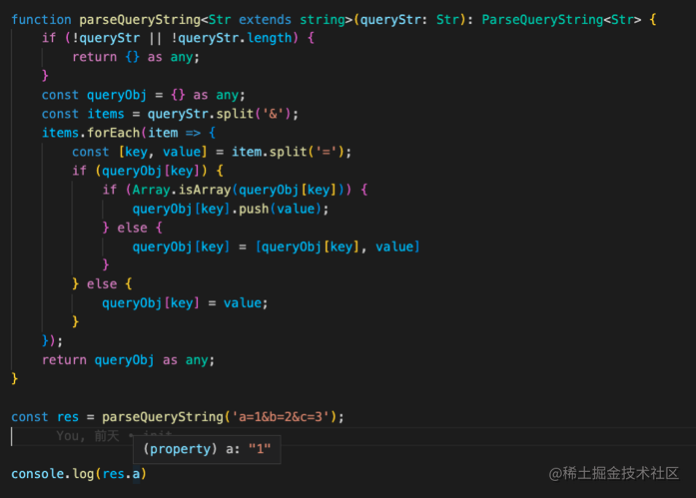
参考文档
Promise
// 判断变量否为function
const isFunction = variable => typeof variable === 'function'
// 定义Promise的三种状态常量
const PENDING = 'PENDING'
const FULFILLED = 'FULFILLED'
const REJECTED = 'REJECTED'
class MyPromise {
constructor (handle) {
if (!isFunction(handle)) {
throw new Error('MyPromise must accept a function as a parameter')
}
// 添加状态
this._status = PENDING
// 添加状态
this._value = undefined
// 添加成功回调函数队列
this._fulfilledQueues = []
// 添加失败回调函数队列
this._rejectedQueues = []
// 执行handle
try {
handle(this._resolve.bind(this), this._reject.bind(this))
} catch (err) {
this._reject(err)
}
}
// 添加resovle时执行的函数
_resolve (val) {
const run = () => {
if (this._status !== PENDING) return
// 依次执行成功队列中的函数,并清空队列
const runFulfilled = (value) => {
let cb;
while (cb = this._fulfilledQueues.shift()) {
cb(value)
}
}
// 依次执行失败队列中的函数,并清空队列
const runRejected = (error) => {
let cb;
while (cb = this._rejectedQueues.shift()) {
cb(error)
}
}
/* 如果resolve的参数为Promise对象,则必须等待该Promise对象状态改变后,
当前Promsie的状态才会改变,且状态取决于参数Promsie对象的状态
*/
if (val instanceof MyPromise) {
val.then(value => {
this._value = value
this._status = FULFILLED
runFulfilled(value)
}, err => {
this._value = err
this._status = REJECTED
runRejected(err)
})
} else {
this._value = val
this._status = FULFILLED
runFulfilled(val)
}
}
// 为了支持同步的Promise,这里采用异步调用
setTimeout(run, 0)
}
// 添加reject时执行的函数
_reject (err) {
if (this._status !== PENDING) return
// 依次执行失败队列中的函数,并清空队列
const run = () => {
this._status = REJECTED
this._value = err
let cb;
while (cb = this._rejectedQueues.shift()) {
cb(err)
}
}
// 为了支持同步的Promise,这里采用异步调用
setTimeout(run, 0)
}
// 添加then方法
then (onFulfilled, onRejected) {
const { _value, _status } = this
// 返回一个新的Promise对象
return new MyPromise((onFulfilledNext, onRejectedNext) => {
// 封装一个成功时执行的函数
let fulfilled = value => {
try {
if (!isFunction(onFulfilled)) {
onFulfilledNext(value)
} else {
let res = onFulfilled(value);
if (res instanceof MyPromise) {
// 如果当前回调函数返回MyPromise对象,必须等待其状态改变后在执行下一个回调
res.then(onFulfilledNext, onRejectedNext)
} else {
//否则会将返回结果直接作为参数,传入下一个then的回调函数,并立即执行下一个then的回调函数
onFulfilledNext(res)
}
}
} catch (err) {
// 如果函数执行出错,新的Promise对象的状态为失败
onRejectedNext(err)
}
}
// 封装一个失败时执行的函数
let rejected = error => {
try {
if (!isFunction(onRejected)) {
onRejectedNext(error)
} else {
let res = onRejected(error);
if (res instanceof MyPromise) {
// 如果当前回调函数返回MyPromise对象,必须等待其状态改变后在执行下一个回调
res.then(onFulfilledNext, onRejectedNext)
} else {
//否则会将返回结果直接作为参数,传入下一个then的回调函数,并立即执行下一个then的回调函数
onFulfilledNext(res)
}
}
} catch (err) {
// 如果函数执行出错,新的Promise对象的状态为失败
onRejectedNext(err)
}
}
switch (_status) {
// 当状态为pending时,将then方法回调函数加入执行队列等待执行
case PENDING:
this._fulfilledQueues.push(fulfilled)
this._rejectedQueues.push(rejected)
break
// 当状态已经改变时,立即执行对应的回调函数
case FULFILLED:
fulfilled(_value)
break
case REJECTED:
rejected(_value)
break
}
})
}
// 添加catch方法
catch (onRejected) {
return this.then(undefined, onRejected)
}
// 添加静态resolve方法
static resolve (value) {
// 如果参数是MyPromise实例,直接返回这个实例
if (value instanceof MyPromise) return value
return new MyPromise(resolve => resolve(value))
}
// 添加静态reject方法
static reject (value) {
return new MyPromise((resolve ,reject) => reject(value))
}
// 添加静态all方法
static all (list) {
return new MyPromise((resolve, reject) => {
/**
* 返回值的集合
*/
let values = []
let count = 0
for (let [i, p] of list.entries()) {
// 数组参数如果不是MyPromise实例,先调用MyPromise.resolve
this.resolve(p).then(res => {
values[i] = res
count++
// 所有状态都变成fulfilled时返回的MyPromise状态就变成fulfilled
if (count === list.length) resolve(values)
}, err => {
// 有一个被rejected时返回的MyPromise状态就变成rejected
reject(err)
})
}
})
}
// 添加静态race方法
static race (list) {
return new MyPromise((resolve, reject) => {
for (let p of list) {
// 只要有一个实例率先改变状态,新的MyPromise的状态就跟着改变
this.resolve(p).then(res => {
resolve(res)
}, err => {
reject(err)
})
}
})
}
finally (cb) {
return this.then(
value => MyPromise.resolve(cb()).then(() => value),
reason => MyPromise.resolve(cb()).then(() => { throw reason })
);
}
}
JS 面向对象、prototype 和 __proto__
prototype 和 __proto__ 由来
- 没有class 关键字,使用函数代替
早期的 js 并没有 class 关键字,所以使用 js 函数替代,实现面向对象的能力;
// 构造函数
function Puppy() {}
// 实例化
var myPuppy = new Puppy();
但这样的设计缺少了构造函数,无法在构造函数中对实例做特殊配置,如上面例子中无法设置 myPuppy 的年龄;
函数本身就是构造函数
当做类用的函数本身也是一个函数,而且他就是默认的构造函数。我们想让Puppy函数能够设置实例的年龄,只要让他接收参数就行了。
function Puppy(age) {
this.puppyAge = age;
}
// 实例化时可以传年龄参数了
const myPuppy = new Puppy(2);
注意上面代码的this,被作为类使用的函数里面this总是指向实例化对象,也就是myPuppy。这么设计的目的就是让使用者可以通过构造函数给实例对象设置属性,这时候console出来看myPuppy.puppyAge就是2。
console.log(myPuppy.puppyAge); // 输出是 2
实例方法用prototype
上面我们实现了类和构造函数,但是类方法呢?Java版小狗还可以“汪汪汪”叫呢,JS版怎么办呢?JS给出的解决方案是给方法添加一个prototype属性,挂载在这上面的方法,在实例化的时候会给到实例对象。我们想要myPuppy能说话,就需要往Puppy.prototype添加说话的方法。
Puppy.prototype.say = function() {
console.log("汪汪汪");
}
实例方法查找用__proto__
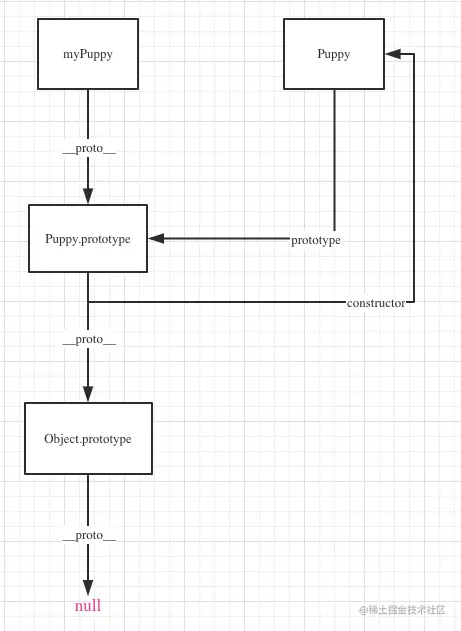
实例对象上并不存在构造函数上的方法,在查找对应的方法的时候,就需要使用 __proto__,当访问一个对象上没有的属性时,比如 myPuppy.say,对象会去__proto__查找。__proto__的值就等于父类的prototype, myPuppy.__proto__指向了Puppy.prototype
myPuppy.__proto__ === Puppy.prototype
如果你访问的属性在Puppy.prototype也不存在,那又会继续往Puppy.prototype.__proto__上找,这时候其实就找到了Object.prototype了,Object.prototype再往上找就没有了,也就是 null,这其实就是原型链。
constructor
我们说的constructor一般指类的prototype.constructor。prototype.constructor是prototype上的一个保留属性,这个属性就指向类函数本身,用于指示当前类的构造函数。
Puppy.prototype.constructor = Puppy
既然prototype.constructor是指向构造函数的一个指针,那我们是不是可以通过它来修改构造函数呢?我们来试试就知道了。我们先修改下这个函数,然后新建一个实例看看效果:
function Puppy(age) {
this.puppyAge = age;
}
Puppy.prototype.constructor = function myConstructor(age) {
this.puppyAge = age + 1;
}
const myPuppy2 = new Puppy(2);
console.log(myPuppy2.puppyAge); // 输出是2
通过下面一张图来描述三者的关系:
实现一个new
结合上面讲的, new其实就是生成了一个对象,这个对象能够访问类的原型,知道了原理,我们就可以自己实现一个new了。
function myNew(func, ...args) {
const obj = {}; // 1. 新建一个空对象
const result = func.call(obj, ...args); // 2. 执行构造函数
obj.__proto__ = func.prototype; // 3.设置原型链
// 4. 注意如果原构造函数有Object类型的返回值,包括Functoin, Array, Date, RegExg, Error
// 那么应该返回这个返回值
const isObject = typeof result === 'object' && result !== null;
const isFunction = typeof result === 'function';
if(isObject || isFunction) {
return result;
}
// 原构造函数没有Object类型的返回值,返回我们的新对象
return obj;
}
function Puppy(age) {
this.puppyAge = age;
}
Puppy.prototype.say = function() {
console.log("汪汪汪");
}
const myPuppy3 = myNew(Puppy, 2);
console.log(myPuppy3.puppyAge); // 2
console.log(myPuppy3.say()); // 汪汪汪
实现一个instanceof
instanceof 就是检查一个对象是不是某个类的实例,换句话说就是检查一个对象的的原型链上有没有这个类的prototype,知道了这个我们就可以自己实现一个了:
function myInstanceof(targetObj, targetClass) {
// 参数检查
if(!targetObj || !targetClass || !targetObj.__proto__ || !targetClass.prototype){
return false;
}
let current = targetObj;
while(current) { // 一直往原型链上面找
if(current.__proto__ === targetClass.prototype) {
return true; // 找到了返回true
}
current = current.__proto__;
}
return false; // 没找到返回false
}
// 用我们前面的继承实验下
function Parent() {}
function Child() {}
Child.prototype.__proto__ = Parent.prototype;
const obj = new Child();
console.log(myInstanceof(obj, Child)); // true
console.log(myInstanceof(obj, Parent)); // true
console.log(myInstanceof({}, Parent)); // false
总结
- JS中的函数可以作为函数使用,也可以作为类使用
- 作为类使用的函数实例化时需要使用new
- 为了让函数具有类的功能,函数都具有
prototype属性。 - 为了让实例化出来的对象能够访问到
prototype上的属性和方法,实例对象的__proto__指向了类的prototype。所以prototype是函数的属性,不是对象的。对象拥有的是__proto__,是用来查找prototype的。 prototype.constructor指向的是构造函数,也就是类函数本身。改变这个指针并不能改变构造函数。- 对象本身并没有
constructor属性,你访问到的是原型链上的prototype.constructor。 - 函数本身也是对象,也具有
__proto__,他指向的是JS内置对象Function的原型Function.prototype。所以你才能调用func.call,func.apply这些方法,你调用的其实是Function.prototype.call和Function.prototype.apply。 prototype本身也是对象,所以他也有__proto__,指向了他父级的prototype。__proto__和prototype的这种链式指向构成了JS的原型链。原型链的最终指向是Object的原型。Object上面原型链是null,即Object.prototype.__proto__ === null。- 另外
Function.__proto__ === Function.prototype,这是因为JS中所有函数的原型都是Function.prototype,也就是说所有函数都是Function的实例。Function本身也是可以作为函数使用的––Function(),所以他也是Function的一个实例。类似的还有Object,Array等,他们也可以作为函数使用:Object(),Array()。所以他们本身的原型也是Function.prototype,即Object.__proto__ === Function.prototype。换句话说,这些可以new的内置对象其实都是一个类,就像我们的Puppy类一样。 - ES6的class其实是函数类的一种语法糖,书写起来更清晰,但原理是一样的。
参考文档
V8 浏览器内核
提到浏览器内核,Blink、Weikit、Gecko、Trident 张口就来,这些只是各个浏览器内核的组成部分之一渲染引擎,对应的还有 JavaScript引擎,简单罗列一下:
| 浏览器 | 渲染引擎 | Javascript 引擎 |
|---|---|---|
| Chrome | Blink(13 年之前使用的是 Safari 的 Webkit, Blink 是谷歌与欧朋一起搞的) | V8 |
| Safari | Webkit | JavaScriptCore |
| Firefox | Gecko | SpiderMonkey–OdinMonkey |
| IE | Trident | Chakra |
渲染引擎和 JS 引擎相互协作,打造出浏览器显示的页面,看下图:
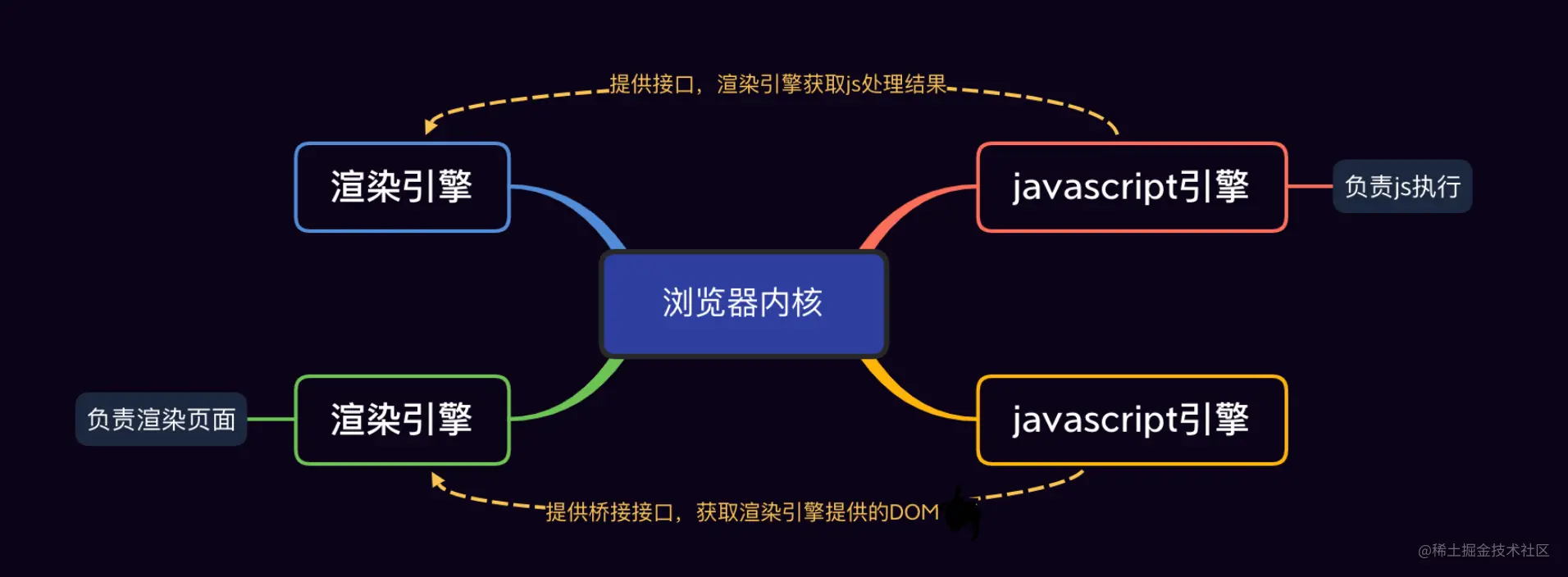
简单看看就行,不重要,既然是讲垃圾回收( Garbage Collection 简称 GC ),那就要先去回收站了,回收站有个学名叫:内存,计算机五大硬件之一存储器的核心之一,见下图:
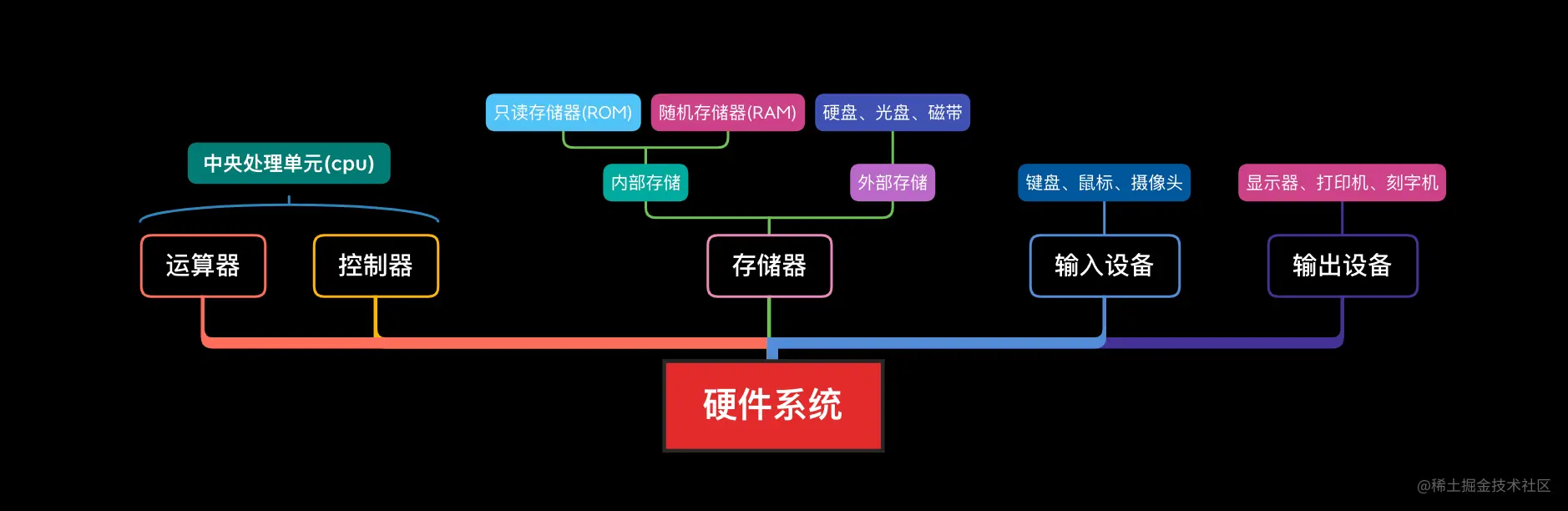
说句更不重要的,JS 是没有能力管理内存和垃圾回收的,一切都要依赖各个浏览器的 JS 引擎,所以为了逼格更高一点,就不要说 JS 垃圾回收了,你看,我说 V8 垃圾回收,是不是厉害多了(摸了摸越来越没有阻力的脑袋)。
内存分配
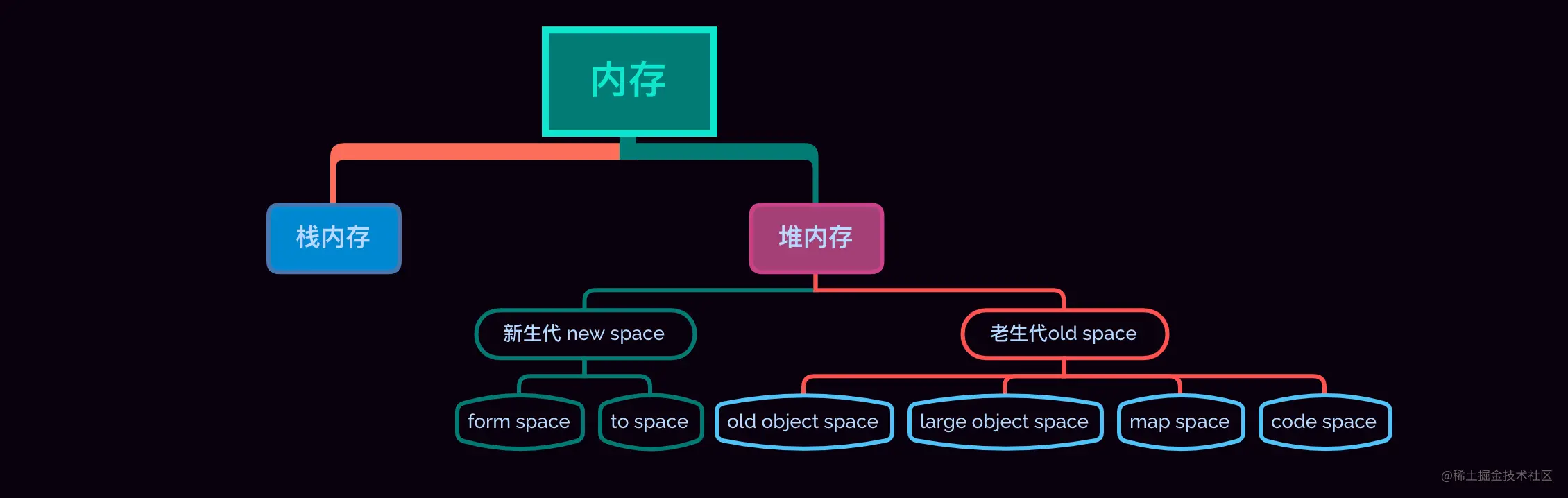
栈
简单说,栈内存,小且存储连续,操作起来简单方便,一般由系统自动分配,自动回收,所以文章内所说的垃圾回收,都是基于堆内存。
堆
堆内存,大(相对栈来说)且不连续。
V8 中内存分类
在讲内存分配之前,先了解一下弱分代假说,V8 的垃圾回收主要建立在这个假说之上。
概念:
- 绝大部分的对象生命周期都很短,即存活时间很短
- 生命周期很长的对象,基本都是常驻对象
基于以上两个概念,将内存分为新生代 (new space) 与 老生代(old space) 两个区域。划重点,记一下。
垃圾回收
新生代
新生代(32 位系统分配 16M 的内存空间,64 位系统翻倍 32M,不同浏览器可能不同,但是应该差不了多少)。 新生代对应存活时间很短的假说概念,这个空间的操作,非常频繁,绝大多数对象在这里经历一次生死轮回,基本消亡,没消亡的会晋升至老生代内。
新生代算法为 Scavenge 算法,典型牺牲空间换时间的败家玩意,怎么说呢?首先他将新生代分为两个相等的半空间( semispace ) from space 与 to space,来看看这个败家玩意,是怎么操作的,他使用宽度优先算法,是宽度优先,记住了不。两个空间,同一时间内,只会有一个空间在工作( from space ),另一个在休息( to space )。
- 首先,V8 引擎中的垃圾回收器检测到 from space 空间快达到上限了,此时要进行一次垃圾回收了
- 然后,从根部开始遍历,不可达对象(即无法遍历到的对象)将会被标记,并且复制未被标记的对象,放到 to space 中
- 最后,清除 from space 中的数据,同时将 from space 置为空闲状态,即变成 to space,相应的 to space 变成 from space,俗称翻转
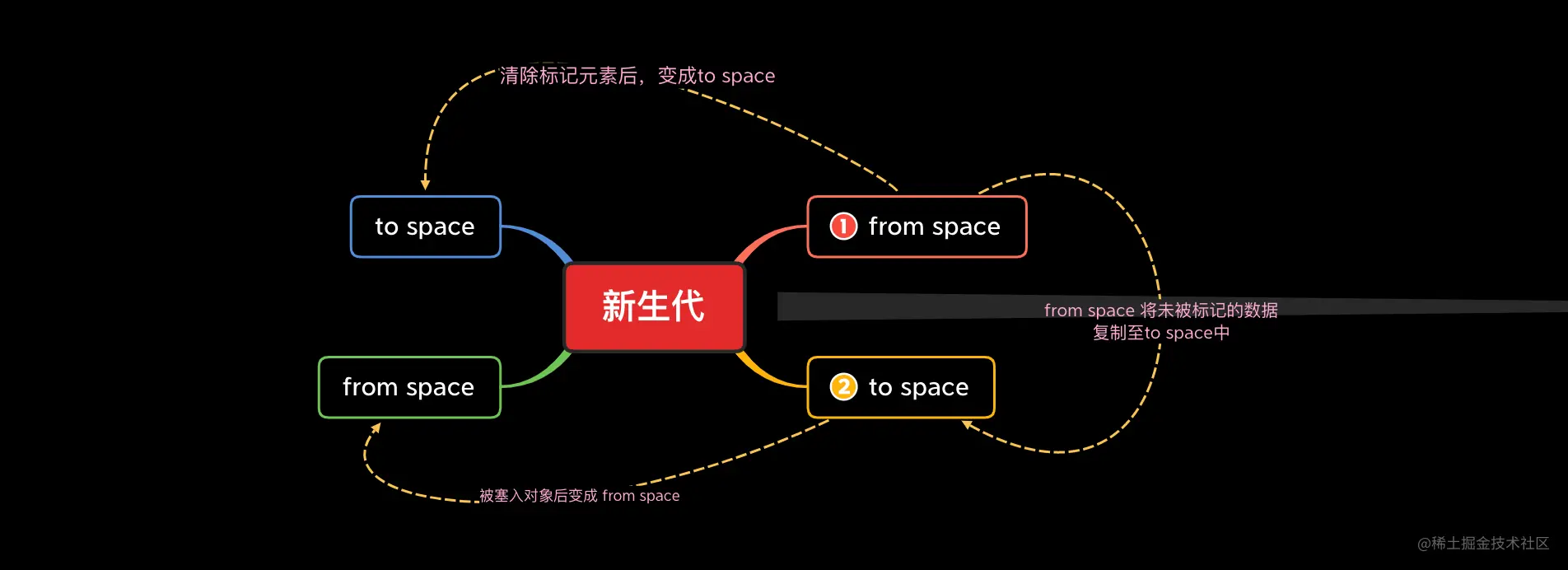
也是,你说空间都给他了,他爱咋地处理就咋地处理呗,总不可能强迫王校长开二手奥拓吧,当然了,对于小对象,这么来一次,时间的优势那是杠杠的,虽然浪费了一半空间,但是问题不大,能 hold 住。
当然优秀的 V8 是不可能容忍,一个对象来回的在 form space 和 to space 中蹦跶的,当经历一次 form => to 翻转之后,发现某些未被标记的对象居然还在,会直接扔到老生代里面去,好似后浪参加比赛,晋级了,优秀的嘞。
除了上面一种情况,还有一个情况也会晋级,当一个对象,在被复制的时候,大于 to space 空间的 25% 的时候,也会晋级了,这种自带背景的选手,那是不敢动的,直接晋级到老生代。
老生代
老生代( 32 位操作系统分配大约 700M 内存空间,64 位翻倍 1.4G,一样,每个浏览器可能会有差异,但是差不了多少)。 老生代比起新生代可是要复杂的多,所谓能者多劳,空间大了,责任就大了,老生代可以分为以下几个区域:
- old object space 即大家口中的老生代,不是全部老生代,这里的对象大部分是由新生代晋升而来
- large object space 大对象存储区域,其他区域无法存储下的对象会被放在这里,基本是超过 1M 的对象,这种对象不会在新生代对象中分配,直接存放到这里,当然了,这么大的数据,复制成本很高,基本就是在这里等待命运的降临不可能接受仅仅是知其然,而不知其所以然
- Map space 这个玩意,就是存储对象的映射关系的,其实就是隐藏类,啥是隐藏类?就不告诉你(不知道的大佬已经去百度了)
- code space 简单点说,就是存放代码的地方,编译之后的代码,是根据大佬们写的代码编译出来的代码
看个图,休息一下:
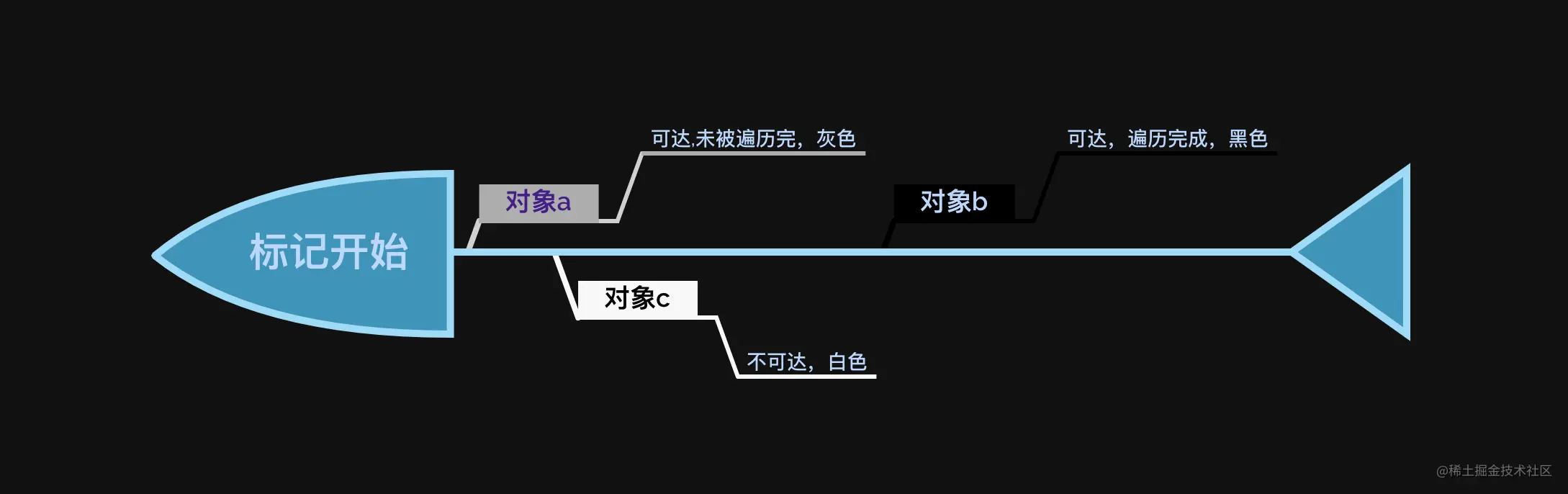
讲了这么多基本概念,聊聊最后的老生代回收算法,老生代回收算法为:标记和清除/整理(mark-sweep/mark-compact)。 在标记的过程中,引入了概念:三色标记法,三色为:
- 白:未被标记的对象,即不可达对象(没有扫描到的对象),可回收
- 灰:已被标记的对象(可达对象),但是对象还没有被扫描完,不可回收
- 黑:已被扫描完(可达对象),不可回收
当然,既然要标记,就需要提供记录的坑位,在 V8 中分配的每一个内存页中创建了一个 marking bitmap 坑位。 大致的流程为:
- 首先将所有的非根部对象全部标记为白色,然后使用深度优先遍历,是深度优先哈,和新生代不一样哈,按深度优先搜索沿途遍历,将访问到的对象,直接压入栈中,同时将标记结果放在 marking bitmap (灰色) 中,一个对象遍历完成,直接出栈,同时在 marking bitmap 中记录为黑色,直到栈空为止,来张图,休息一下
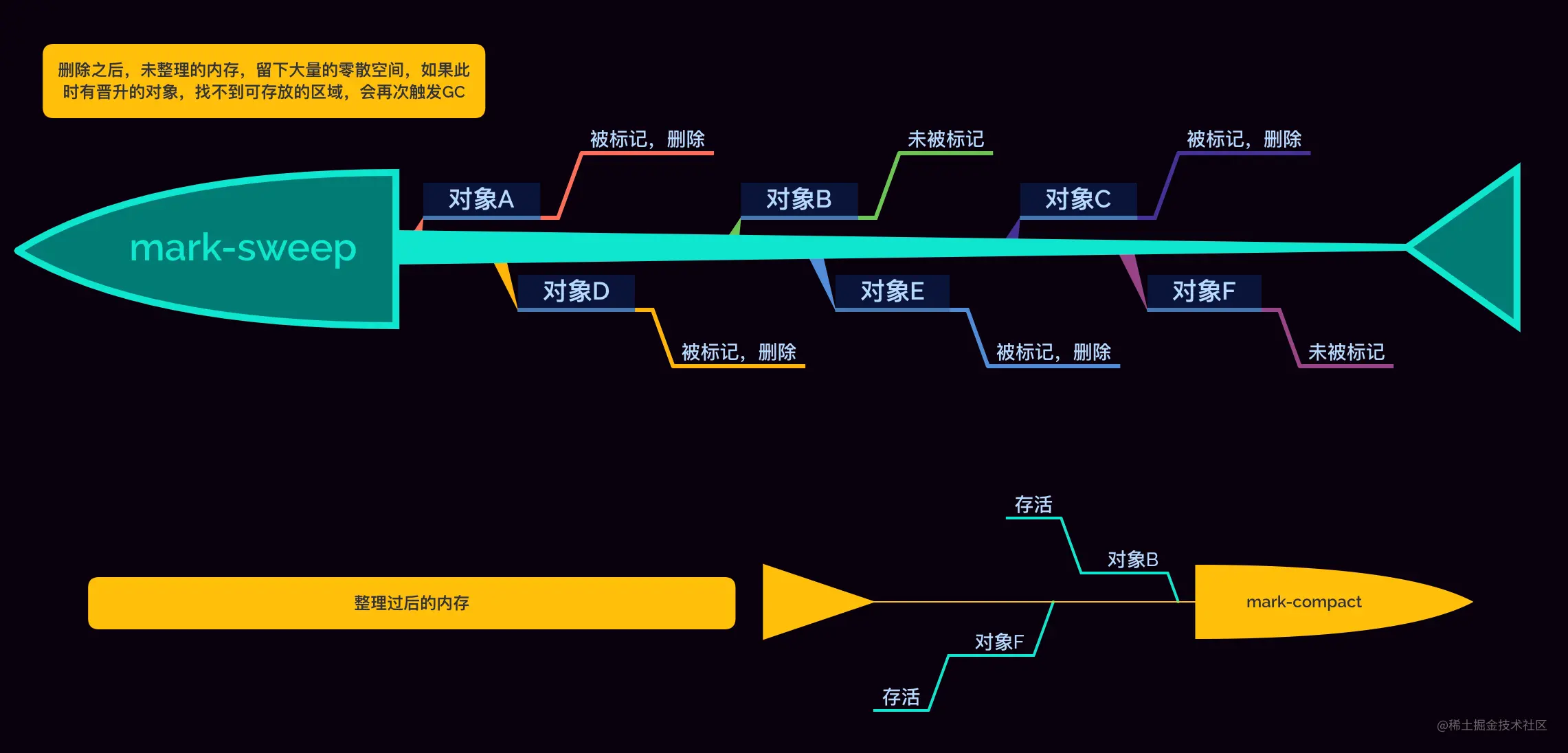
 2. 标记完成后,接下来就是等待垃圾回收器来清除了,清除完了之后,会在原来的内存区域留下一大堆不连续的空间,小对象还好说,这个时候如果来一个稍微大一点的对象,没有内存可以放的下这个傻大个了,怎么办?只能触发 GC,但是吧,原来清除的不连续的空间加起来又可以放的下这个傻大个,很可惜啊,启动一次 GC 性能上也是嗖嗖的往下掉啊;V8 能容许这样的事发生?肯定不存在嘛!
3. 所以在清除完之后,新生代中对象,再一次分配到老生代并且内存不足的时候,会优先触发标记整理(mark-compact), 在标记结束后,他会将可达对象(黑色),移到内存的另一端,其他的内存空间就不会被占用,直接释放,等下次再有对象晋升的时候,轻松放下。
2. 标记完成后,接下来就是等待垃圾回收器来清除了,清除完了之后,会在原来的内存区域留下一大堆不连续的空间,小对象还好说,这个时候如果来一个稍微大一点的对象,没有内存可以放的下这个傻大个了,怎么办?只能触发 GC,但是吧,原来清除的不连续的空间加起来又可以放的下这个傻大个,很可惜啊,启动一次 GC 性能上也是嗖嗖的往下掉啊;V8 能容许这样的事发生?肯定不存在嘛!
3. 所以在清除完之后,新生代中对象,再一次分配到老生代并且内存不足的时候,会优先触发标记整理(mark-compact), 在标记结束后,他会将可达对象(黑色),移到内存的另一端,其他的内存空间就不会被占用,直接释放,等下次再有对象晋升的时候,轻松放下。
看到这里各位大佬可能会有疑问,那要是我 GC 搞完之后,再来个对象,满了咋办,你说咋办,直接崩好不好,这个时候就需要大佬们写代码的时候,要珍惜内存了,对内存就像珍惜你的女朋友一样,啥?没有女朋友? 那就没办法了,原则上是决不了这个问题的。
基本的内存和垃圾回收是交代完了,其中还有一些概念,还是要说一下的,接着往下看!
写屏障
想一个问题,当 GC 想回收新生代中的内容的时候,某些对象,只有一个指针指向了他,好巧不巧的是,这个指针还是老生代那边对象指过来的,怎么搞?我想回收这个玩意,难道要遍历一下老生代中的对象吗?这不是开玩笑吗?为了回收这一个玩意,我需要遍历整个老生代,代价着实太大,搞不起,搞不起,那怎么办哩? V8 引擎中有个概念称作写屏障,在写入对象的地方有个缓存列表,这个列表内记录了所有老生代指向新生代的情况,当然了新生成的对象,并不会被记录,只有老生代指向新生代的对象,才会被写入这个缓存列表。 在新生代中触发 GC 遇到这样的对象的时候,会首先读一下缓存列表,这相比遍历老生代所有的对象,代价实在是太小了,这操作值得一波 666,很优秀,当然了,关于 V8 引擎内在的优化,还有很多很多,各位大佬可以慢慢去了解。
全停顿(stop-the-world)
关于全停顿,本没有必要单独来讲,但是,I happy 就 good。 在以往,新/老生带都包括在内,为了保证逻辑和垃圾回收的情况不一致,需要停止 JS 的运行,专门来遍历去遍历/复制,标记/清除,这个停顿就是:全停顿。 这就比较恶心了,新生代也就算了,本身内存不大,时间上也不明显,但是在老生代中,如果遍历的对象太多,太大,用户在此时,是有可能明显感到页面卡顿的,体验嘎嘎差。 所以在 V8 引擎在名为 Orinoco 项目中,做了三个事情,当然只针对老生代,新生代这个后浪还是可以的,效率贼拉的高,优化空间不大。三个事情分别是:
- 增量标记
将原来一口气去标记的事情,做成分步去做,每次内存占用达到一定的量或者多次进入写屏障的时候,就暂时停止 JS 程序,做一次最多几十毫秒的标记 marking,当下次 GC 的时候,反正前面都标记好了,开始清除就行了
- 并行回收
从字面意思看并行,就是在一次全量垃圾回收的过程中,就是 V8 引擎通过开启若干辅助线程,一起来清除垃圾,可以极大的减少垃圾回收的时间,很优秀,手动点赞
- 并发回收
并发就是在 JS 主线程运行的时候,同时开启辅助线程,清理和主线程没有任何逻辑关系的垃圾,当然,需要写屏障来保障
小结
V8 引擎做的优化有很多,还有比如多次( 2 次)在新生代中能够存活下来的对象,会被记录下来,在下次 GC 的时候,会被直接晋升到老生代,还有比如新晋升的对象,直接标记为黑色,这是因为新晋升的对象存活下来的概率非常高,这两种情况就算是不再使用,再下下次的时候也会被清除掉,影响不大,但是这个过程,第一种就省了新生代中的一次复制轮回,第二种就省了 marking 的过程,在此类对象比较多的情况下,还是比较有优势的。
参考文档
防抖与节流
防抖 debounce
- 定义
在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时。(延迟执行,重复触发时,取消上一个计时,重新开始倒计时)
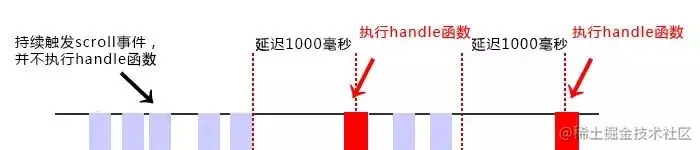
- 适用场景
- 窗口的resize、scroll
- 输入框内容校验
- 实现
function debounce(fun, delay) {
return function (args) {
let that = this
let _args = args
clearTimeout(fun.id)
fun.id = setTimeout(function () {
fun.call(that, _args)
}, delay)
}
}
// 使用方法
let inputb = document.getElementById('debounce')
let debounceAjax = debounce(ajax, 500)
inputb.addEventListener('keyup', function (e) {
debounceAjax(e.target.value)
})
节流
- 定义
规定在一个单位时间内,只能触发一次函数。如果这个单位时间内触发多次函数,只有一次生效。(以固定频率执行)
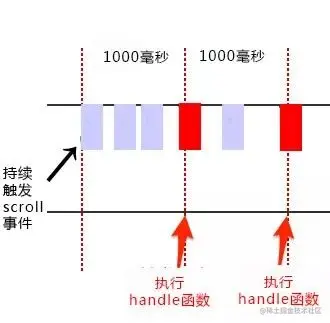
- 适用场景
- 鼠标不断点击触发,mousedown(单位时间内只触发一次)
- 监听滚动事件,比如是否滑到底部自动加载更多,用throttle来判断
- 实现
function throttle(fun, delay) {
let last, deferTimer
return function () {
let that = this;
let _args = arguments;
let now = Date.now();
if (last && now < last + delay) {
clearTimeout(deferTimer);
deferTimer = setTimeout(function () {
last = now;
fun.apply(that, _args);
}, delay);
} else {
last = now;
fun.apply(that, _args);
}
}
}
// 使用方式
let throttleAjax = throttle(ajax, 1000)
let inputc = document.getElementById('throttle')
inputc.addEventListener('keyup', function(e) {
throttleAjax(e.target.value)
});
defer 与 async
defer 和 async 在网络读取(下载脚本)时行为类似,均是异步的(相较于 HTML 解析) 两者区别在于:
- 脚本异步下载完之后执行的时机:defer 会在所有文档元素解析完成后,DOMContentLoaded 事件触发之前执行;async 会在脚本异步下载完成后立刻执行。
- 脚本异步下载完之后的加载顺序:defer 按照脚本开始下载的顺序执行脚本;async 则是下载完后就执行,是乱序执行,因为 async 脚本的加载和执行是紧挨着执行的,因此哪个脚本先加载完成就会先执行哪个。
defer 按照脚本声明顺序执行,async 按照脚本加载完成的先后顺序执行。
async 对于应用脚本的用处不大,因为它完全不考虑依赖(哪怕是最低级的顺序执行),不过它对于那些可以不依赖任何脚本或不被任何脚本依赖的脚本来说却是非常合适的。
requestAnimationFrame
- 定义:告知浏览器在下一次重绘前,调用其回调函数来更新动画。
- 内部执行机制:
- 首先判断
document.hidden属性是否可见(true),可见状态下才能继续执行以下步骤。 - 浏览器清空回调队列中的动画函数。
requestAnimationFrame()将回调函数追加到动画帧请求回调函数列表的末尾。 >注意:执行requestAnimationFrame(callback)不会立即调用 callback 回调函数,只是将其放入动画帧请求回调函数队列(不知道是不是浏览器维护回流/重绘操作的队列?总之该队列是与宏任务/微任务等回调队列独立开的)而已,同时注意,每个 callback回调函数都有一个 cancelled 标志符,初始值为 false,并对外不可见。- 当页面可见并且动画帧请求callback回调函数列表不为空时,浏览器会定期将这些回调函数加入到浏览器 UI 线程的队列中(由系统来决定回调函数的执行时机)。
当浏览器执行这些 callback 回调函数的时候,会判断每个元组的 callback 的cancelled标志符,只有 cancelled 为 false 时,才执行callback回调函数(若被
cancelAnimationFrame()取消了,对应 callback 的 cancelled 标识符会被置为 true)。
特点:
1. 定时动画存在的问题
- setTimeout / setInterval 不能保证回调的运行时刻:计时器只能保证何时将回调添加至浏览器的回调队列(宏任务),不能保证回调队列的运行时间,假设主线程被其他任务占用,那么回调队列中的动画任务就会被阻塞,而不会按照原定的时间间隔刷新绘制。
- setTimeout / setInterval 计时不精确:不同浏览器的计时器精度都存在误差,此外浏览器会对切换到后台或不活跃标签页中的计时器进行限流,导致计时器计时误差。
- setTimeout / setInterval 在后台运行增大 CPU 开销:当标签页处于非活跃状态,计时器仍在执行计时工作,同时刷新动画效果,增大了 CPU 开销。(现阶段浏览器对此做了优化,如 FireFox/Chrome 浏览器对定时器做了优化:页面闲置时,如果时间间隔小于 1000ms,则停止定时器,与requestAnimationFrame行为类似。如果时间间隔>=1000ms,定时器依然在后台执行)
2. requestAnimationFrame 动画刷新机制的特点
- requestAnimationFrame 采用系统时间间隔来执行回调函数,保持最佳绘制效率,不会因为间隔时间的过短,造成过度绘制,增加页面开销,也不会因为间隔时间过长,造成动画卡顿,不流程,影响页面美观。
requestAnimationFrame的基本思想:让页面重绘的频率和刷新频率保持同步,即每 1000ms / 60 = 16.7ms执行一次。由于每次执行动画帧回调是由浏览器重回频率决定的,因此不需要像 setTimeout 那样传递时间间隔,而是浏览器通过系统获取并使用显示器刷新频率。
- requestAnimationFrame 自带节流功能,例如在某些高频事件(resize,scroll 等)中,requestAnimationFrame 依据系统时间间隔来调用回调,可以防止在一个刷新间隔内发生多次函数执行。
- requestAnimationFrame 延时效果是精确的,即在每次页面重绘前必会清空一次动画帧回调队列。(setTimeout 任务被放进异步队列中,只有当主线程上的任务执行完以后,才会去检查该队列的任务是否需要开始执行,造成时间延时)。
- requestAnimationFrame 会把每一帧中的所有DOM操作集中起来,在一次重绘或回流中完成。
- setTimeout 的执行只是在内存中对图像属性进行改变,这个改变必须要等到下次浏览器重绘时才会被更新到屏幕上。如果和屏幕刷新步调不一致,就可能导致中间某些帧的操作被跨越过去,直接更新下下一帧的图像,即掉帧。使用 requestAnimationFrame 执行动画,最大优势是能保证动画帧回调队列中的回调函数在屏幕每一次刷新前都被执行一次,然后将结果一起重绘到浏览器页面,这样就不会引起丢帧,动画也就不会卡顿。
- requestAnimationFrame() 只有当标签页处于活跃状态是才会执行,当页面隐藏或最小化时,会被暂停,页面显示,会继续执行,节省了 CPU 开销。早期浏览器会对切换至后台或不活跃的标签页中的计时器执行限流,导致计时器时间不精确,此外计时器在后台仍会进行计时工作,执行动画任务,此时刷新动画是完全没有意义的。
node 专题
模块分类
node 模块分为两类:
- 系统模块
- C/C++ 模块,也叫 built-in 内建模块,一般用于 native 模块调用,再 require 出去
- native 模块,在开发中使用的 Node.js 的 http、buffer、fs 等,底层也是调用的内建模块 (C/C++)。
- 第三方模块 非 Node.js 自带的模块称为第三方模块,其实还分为路径形式的文件模块(以 .、..、/ 开头的)和自定义的模块(比如 express、koa 框架、moment.js 等)
- javaScript 模块:例如 hello.js
- json 模块:例如 hello.json
- C/C++ 模块:编译之后扩展名为 .node 的模块,例如 hello.node
模块加载机制
在 Node.js 中模块加载一般会经历 3 个步骤:路径分析、文件定位、编译执行。
按照模块的分类,按照以下顺序进行优先加载:
- 系统缓存:模块被执行之后会会进行缓存,首先是先进行缓存加载,判断缓存中是否有值。
- 系统模块:也就是原生模块,这个优先级仅次于缓存加载,部分核心模块已经被编译成二进制,省略了
路径分析、文件定位,直接加载到了内存中,系统模块定义在 Node.js 源码的 lib 目录下,可以去查看。 - 文件模块:优先加载
.、..、/开头的,如果文件没有加上扩展名,会依次按照.js、.json、.node进行扩展名补足尝试,那么在尝试的过程中也是以同步阻塞模式来判断文件是否存在,从性能优化的角度来看待,.json、.node最好还是加上文件的扩展名。 - 目录做为模块:这种情况发生在文件模块加载过程中也没有找到,但是发现是一个目录的情况,这个时候会将这个目录当作一个
包来处理,Node 这块采用了 Commonjs 规范,先会在项目根目录查找 package.json 文件,取出文件中定义的 main 属性("main": "lib/hello.js")描述的入口文件进行加载,也没加载到,则会抛出默认错误: Error: Cannot find module ‘lib/hello.js’ - node_modules 目录加载:对于系统模块、路径文件模块都找不到,Node.js 会从当前模块的父目录进行查找,直到系统的根目录
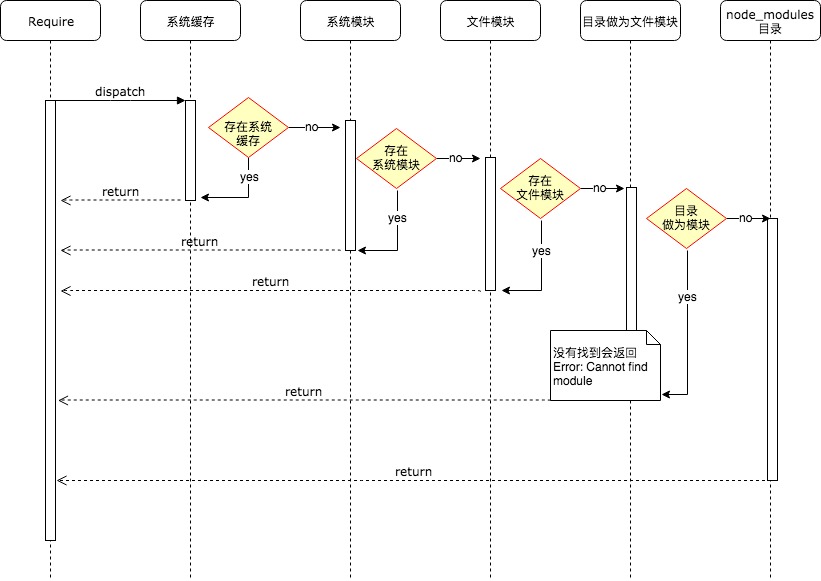
模块缓存在哪
Node.js 提供了 require.cache API 查看已缓存的模块,返回值为对象;
模块循环引用
// a.js
console.log('a模块start');
exports.test = 1;
undeclaredVariable = 'a模块未声明变量'
const b = require('./b');
exports.test2 = 2;
console.log('a模块加载完毕: b.test值:',b.test);
// b.js
console.log('b模块start');
exports.test = 2;
const a = require('./a');
console.log('undeclaredVariable: ', undeclaredVariable);
console.log('b模块加载完毕: a.test值:', a.test, a.test2);
- 假设有 a.js、b.js 两个模块相互引用,会有什么问题?是否为陷入死循环?看以下例子
- a 模块中的 undeclaredVariable 变量在 b.js 中是否会被打印?
控制台执行node a.js,查看输出结果:
a模块start
b模块start
undeclaredVariable: a模块未声明变量
b模块加载完毕: a.test值: 1 undefined
a模块加载完毕: b.test值: 2
问题1,启动 a.js 的时候,会加载 b.js,那么在 b.js 中又加载了 a.js,但是此时 a.js 模块还没有执行完,返回的是一个 a.js 模块的 exports 对象 未完成的副本(a模块此时只解析到了 const b = require('./b'); 这行, 所以b模块只能拿到这行之前到处的内容) 给到 b.js 模块(因此是不会陷入死循环的)。然后 b.js 完成加载之后将 exports 对象提供给了 a.js 模块;
问题2,因为 undeclaredVariable 是一个未声明的变量,也就是一个挂在全局的变量,那么在其他地方当然是可以拿到的。
在执行代码之前,Node.js 会使用一个代码封装器进行封装,例如下面所示:
(function(exports, require, module, __filename, __dirname) {
// 模块的代码
});
对象引用关系考察
也许是面试考察最多的问题:module.exports 与 exports 的区别?
exports 相当于 module.exports 的快捷方式如下所示:
const exports = modules.exports;
但是要注意不能改变 exports 的指向,我们可以通过 exports.test = 'a' 这样来导出一个对象, 但是不能像下面示例直接赋值,这样会改变 exports 的指向
// 错误的写法 将会得到 undefined
exports = {
'a': 1,
'b': 2
}
// 正确的写法
modules.exports = {
'a': 1,
'b': 2
}
更好的理解之间的关系,可以参考 JavaScript中的对象引用
Buffer
缓冲(Buffer)与缓存(Cache)的区别? Buffer 类是作为 Node.js API 的一部分引入的,用于在 TCP 流、文件系统操作、以及其他上下文中与八位字节流进行交互,这是来自 Node.js 官网的一段描述,比较晦涩难懂,总结起来一句话 Node.js 可以用来处理二进制流数据或者与之进行交互。
Buffer 用于读取或操作二进制数据流,做为 Node.js API 的一部分使用时无需 require,用于操作网络协议、数据库、图片和文件 I/O 等一些需要大量二进制数据的场景。Buffer 在创建时大小已经被确定且是无法调整的,在内存分配这块 Buffer 是由 C++ 层面提供而不是 V8 具体后面会讲解。
什么是 Buffer?
通常,数据的移动是为了处理或者读取它,并根据它进行决策。伴随着时间的推移,每一个过程都会有一个最小或最大数据量。如果数据到达的速度比进程消耗的速度快,那么少数早到达的数据会处于等待区等候被处理。反之,如果数据到达的速度比进程消耗的数据慢,那么早先到达的数据需要等待一定量的数据到达之后才能被处理。
这里的等待区就指的缓冲区(Buffer),它是计算机中的一个小物理单位,通常位于计算机的 RAM 中。这些概念可能会很难理解,不要担心下面通过一个例子进一步说明。
创建Buffer
在 6.0.0 之前的 Node.js 版本中, Buffer 实例是使用 Buffer 构造函数创建的,该函数根据提供的参数以不同方式分配返回的 Buffer new Buffer()。
现在可以通过 Buffer.from()、Buffer.alloc() 与 Buffer.allocUnsafe() 三种方式来创建
Buffer.from()
const b1 = Buffer.from('10');
const b2 = Buffer.from('10', 'utf8');
const b3 = Buffer.from([10]);
const b4 = Buffer.from(b3);
console.log(b1, b2, b3, b4); // <Buffer 31 30> <Buffer 31 30> <Buffer 0a> <Buffer 0a>
Buffer.alloc
返回一个已初始化的 Buffer,可以保证新创建的 Buffer 永远不会包含旧数据。
const bAlloc1 = Buffer.alloc(10); // 创建一个大小为 10 个字节的缓冲区
console.log(bAlloc1); // <Buffer 00 00 00 00 00 00 00 00 00 00>
Buffer.allocUnsafe、Buffer.allocUnsafeSlow
创建一个大小为 size 字节的新的未初始化的 Buffer,由于 Buffer 是未初始化的,因此分配的内存片段可能包含敏感的旧数据。在 Buffer 内容可读情况下,则可能会泄露它的旧数据,这个是不安全的,使用时要谨慎。
const bAllocUnsafe1 = Buffer.allocUnsafe(10);
console.log(bAllocUnsafe1); // <Buffer 49 ae c9 cd 49 1d 00 00 11 4f>
当使用 Buffer.allocUnsafe() 分配新的 Buffer 实例时,4 KiB 以下的分配是从单个预分配的 Buffer 中分割出来的。 这允许应用程序避免创建许多单独分配的 Buffer 实例的垃圾收集开销。 这种方法无需跟踪和清理尽可能多的单个 ArrayBuffer 对象,从而提高了性能和内存使用率。 但是,在开发人员可能需要在不确定的时间内从池中保留一小块内存的情况下,使用 Buffer.allocUnsafeSlow() 创建未池化的 Buffer 实例然后复制出相关位可能是合适的。
Buffer 字符编码
通过使用字符编码,可实现 Buffer 实例与 JavaScript 字符串之间的相互转换,目前所支持的字符编码如下所示:
- ‘ascii’ - 仅适用于 7 位 ASCII 数据。此编码速度很快,如果设置则会剥离高位。
- ‘utf8’ - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8。
- ‘utf16le’ - 2 或 4 个字节,小端序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
- ‘ucs2’ - ‘utf16le’ 的别名。
- ‘base64’ - Base64 编码。当从字符串创建 Buffer 时,此编码也会正确地接受 RFC 4648 第 5 节中指定的 “URL 和文件名安全字母”。
- ‘latin1’ - 一种将 Buffer 编码成单字节编码字符串的方法(由 RFC 1345 中的 IANA 定义,第 63 页,作为 Latin-1 的补充块和 C0/C1 控制码)。
- ‘binary’ - ‘latin1’ 的别名。
- ‘hex’ - 将每个字节编码成两个十六进制的字符。
const buf = Buffer.from('hello world', 'ascii');
console.log(buf.toString('hex')); // 68656c6c6f20776f726c64
字符串与 Buffer 类型互转
字符串转 Buffer
这个相信不会陌生了,通过上面讲解的 Buffer.form() 实现,如果不传递 encoding 默认按照 UTF-8 格式转换存储
const buf = Buffer.from('Node.js 技术栈', 'UTF-8');
console.log(buf); // <Buffer 4e 6f 64 65 2e 6a 73 20 e6 8a 80 e6 9c af e6 a0 88>
console.log(buf.length); // 17
Buffer 转换为字符串
Buffer 转换为字符串也很简单,使用 toString([encoding], [start], [end]) 方法,默认编码仍为 UTF-8,如果不传 start、end 可实现全部转换,传了 start、end 可实现部分转换(这里要小心了)
const buf = Buffer.from('Node.js 技术栈', 'UTF-8');
console.log(buf); // <Buffer 4e 6f 64 65 2e 6a 73 20 e6 8a 80 e6 9c af e6 a0 88>
console.log(buf.length); // 17
console.log(buf.toString('UTF-8', 0, 9)); // Node.js �
运行查看,可以看到以上输出结果为 Node.js � 出现了乱码,为什么?
转换过程中为什么出现乱码?
首先以上示例中使用的默认编码方式 UTF-8,问题就出在这里一个中文在 UTF-8 下占用 3 个字节,技 这个字在 buf 中对应的字节为 8a 80 e6
而我们的设定的范围为 0~9 因此只输出了 8a,这个时候就会造成字符被截断出现乱码。
下面我们改下示例的截取范围:
const buf = Buffer.from('Node.js 技术栈', 'UTF-8');
console.log(buf); // <Buffer 4e 6f 64 65 2e 6a 73 20 e6 8a 80 e6 9c af e6 a0 88>
console.log(buf.length); // 17
console.log(buf.toString('UTF-8', 0, 11)); // Node.js 技
可以看到已经正常输出了
Buffer内存机制
在 Nodejs 中的 内存管理和 V8 垃圾回收机制 一节主要讲解了在 Node.js 的垃圾回收中主要使用 V8 来管理,但是并没有提到 Buffer 类型的数据是如何回收的,下面让我们来了解 Buffer 的内存回收机制。
由于 Buffer 需要处理的是大量的二进制数据,假如用一点就向系统去申请,则会造成频繁的向系统申请内存调用,所以 Buffer 所占用的内存不再由 V8 分配,而是在 Node.js 的 C++ 层面完成申请,在 JavaScript 中进行内存分配。因此,这部分内存我们称之为堆外内存。
注意:以下使用到的 buffer.js 源码为 Node.js v10.x 版本,地址:https://github.com/nodejs/node/blob/v10.x/lib/buffer.js
Buffer内存分配原理
Node.js 采用了 slab 机制进行预先申请、事后分配,是一种动态的管理机制。
使用 Buffer.alloc(size) 传入一个指定的 size 就会申请一块固定大小的内存区域,slab 具有如下三种状态:
- full:完全分配状态
- partial:部分分配状态
- empty:没有被分配状态
8KB 限制
Node.js 以 8KB 为界限来区分是小对象还是大对象,在 buffer.js 中可以看到以下代码
Buffer.poolSize = 8 * 1024; // 102 行,Node.js 版本为 v10.x
在 Buffer 初识 一节里有提到过 Buffer 在创建时大小已经被确定且是无法调整的 到这里应该就明白了。
Buffer 对象分配
以下代码示例,在加载时直接调用了 createPool() 相当于直接初始化了一个 8 KB 的内存空间,这样在第一次进行内存分配时也会变得更高效。另外在初始化的同时还初始化了一个新的变量 poolOffset = 0 这个变量会记录已经使用了多少字节。
Buffer.poolSize = 8 * 1024;
var poolSize, poolOffset, allocPool;
... // 中间代码省略
function createPool() {
poolSize = Buffer.poolSize;
allocPool = createUnsafeArrayBuffer(poolSize);
poolOffset = 0;
}
createPool(); // 129 行
此时,新构造的 slab 如下所示:

现在让我们来尝试分配一个大小为 2048 的 Buffer 对象,代码如下所示:
Buffer.alloc(2 * 1024)
现在让我们先看下当前的 slab 内存是怎么样的?如下所示:

那么这个分配过程是怎样的呢?让我们再看 buffer.js 另外一个核心的方法 allocate(size)
// https://github.com/nodejs/node/blob/v10.x/lib/buffer.js#L318
function allocate(size) {
if (size <= 0) {
return new FastBuffer();
}
// 当分配的空间小于 Buffer.poolSize 向右移位,这里得出来的结果为 4KB
if (size < (Buffer.poolSize >>> 1)) {
if (size > (poolSize - poolOffset))
createPool();
var b = new FastBuffer(allocPool, poolOffset, size);
poolOffset += size; // 已使用空间累加
alignPool(); // 8 字节内存对齐处理
return b;
} else { // C++ 层面申请
return createUnsafeBuffer(size);
}
}
读完上面的代码,已经很清晰的可以看到何时会分配小 Buffer 对象,又何时会去分配大 Buffer 对象。
Buffer 内存分配总结
这块内容着实难理解,翻了几本 Node.js 相关书籍,朴灵大佬的「深入浅出 Node.js」Buffer 一节还是讲解的挺详细的,推荐大家去阅读下。
- 在初次加载时就会初始化 1 个 8KB 的内存空间,buffer.js 源码有体现
- 根据申请的内存大小分为 小 Buffer 对象 和 大 Buffer 对象
- 小 Buffer 情况,会继续判断这个 slab 空间是否足够
- 如果空间足够就去使用剩余空间同时更新 slab 分配状态,偏移量会增加
- 如果空间不足,slab 空间不足,就会去创建一个新的 slab 空间用来分配
- 大 Buffer 情况,则会直接走 createUnsafeBuffer(size) 函数
- 不论是小 Buffer 对象还是大 Buffer 对象,内存分配是在 C++ 层面完成,内存管理在 JavaScript 层面,最终还是可以被 V8 的垃圾回收标记所回收。
Buffer应用场景
I/O 操作
关于 I/O 可以是文件或网络 I/O,以下为通过流的方式将 input.txt 的信息读取出来之后写入到 output.txt 文件,关于 Stream 与 Buffer 的关系不明白的在回头看下 Buffer 初识 一节讲解的 什么是 Stream?、什么是 Buffer?
const fs = require('fs');
const inputStream = fs.createReadStream('input.txt'); // 创建可读流
const outputStream = fs.createWriteStream('output.txt'); // 创建可写流
inputStream.pipe(outputStream); // 管道读写
在 Stream 中我们是不需要手动去创建自己的缓冲区,在 Node.js 的流中将会自动创建。
zlib.js
zlib.js 为 Node.js 的核心库之一,其利用了缓冲区(Buffer)的功能来操作二进制数据流,提供了压缩或解压功能。参考源代码 zlib.js 源码
加解密
在一些加解密算法中会遇到使用 Buffer,例如 crypto.createCipheriv 的第二个参数 key 为 String 或 Buffer 类型,如果是 Buffer 类型,就用到了本篇我们讲解的内容,以下做了一个简单的加密示例,重点使用了 Buffer.alloc() 初始化一个实例(这个上面有介绍),之后使用了 fill 方法做了填充,这里重点在看下这个方法的使用。
buf.fill(value[, offset[, end]][, encoding])
- value: 第一个参数为要填充的内容
- offset: 偏移量,填充的起始位置
- end: 结束填充 buf 的偏移量
- encoding: 编码集
以下为 Cipher 的对称加密 Demo
const crypto = require('crypto');
const [key, iv, algorithm, encoding, cipherEncoding] = [
'a123456789', '', 'aes-128-ecb', 'utf8', 'base64'
];
const handleKey = key => {
const bytes = Buffer.alloc(16); // 初始化一个 Buffer 实例,每一项都用 00 填充
console.log(bytes); // <Buffer 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00>
bytes.fill(key, 0, 10) // 填充
console.log(bytes); // <Buffer 61 31 32 33 34 35 36 37 38 39 00 00 00 00 00 00>
return bytes;
}
let cipher = crypto.createCipheriv(algorithm, handleKey(key), iv);
let crypted = cipher.update('Node.js 技术栈', encoding, cipherEncoding);
crypted += cipher.final(cipherEncoding);
console.log(crypted) // jE0ODwuKN6iaKFKqd3RF4xFZkOpasy8WfIDl8tRC5t0=
Buffer VS Cache
缓冲(Buffer)与缓存(Cache)的区别?
缓冲(Buffer)
缓冲(Buffer)是用于处理二进制流数据,将数据缓冲起来,它是临时性的,对于流式数据,会采用缓冲区将数据临时存储起来,等缓冲到一定的大小之后在存入硬盘中。视频播放器就是一个经典的例子,有时你会看到一个缓冲的图标,这意味着此时这一组缓冲区并未填满,当数据到达填满缓冲区并且被处理之后,此时缓冲图标消失,你可以看到一些图像数据。
缓存(Cache)
缓存(Cache)我们可以看作是一个中间层,它可以是永久性的将热点数据进行缓存,使得访问速度更快,例如我们通过 Memory、Redis 等将数据从硬盘或其它第三方接口中请求过来进行缓存,目的就是将数据存于内存的缓存区中,这样对同一个资源进行访问,速度会更快,也是性能优化一个重要的点。
来自知乎的一个讨论,点击 more 查看
Buffer VS String
通过压力测试来看看 String 和 Buffer 两者的性能如何?
const http = require('http');
let s = '';
for (let i=0; i<1024*10; i++) {
s+='a'
}
const str = s;
const bufStr = Buffer.from(s);
const server = http.createServer((req, res) => {
console.log(req.url);
if (req.url === '/buffer') {
res.end(bufStr);
} else if (req.url === '/string') {
res.end(str);
}
});
server.listen(3000);
以上实例我放在虚拟机里进行测试,你也可以在本地电脑测试,使用 AB 测试工具。
测试 string
看以下几个重要的参数指标,之后通过 buffer 传输进行对比
- Complete requests: 21815
- Requests per second: 363.58 [#/sec] (mean)
- Transfer rate: 3662.39 [Kbytes/sec] received
$ ab -c 200 -t 60 http://192.168.6.131:3000/string

测试 buffer
可以看到通过 buffer 传输总共的请求数为 50000、QPS 达到了两倍多的提高、每秒传输的字节为 9138.82 KB,从这些数据上可以证明提前将数据转换为 Buffer 的方式,可以使性能得到近一倍的提升。
- Complete requests: 50000
- Requests per second: 907.24 [#/sec] (mean)
- Transfer rate: 9138.82 [Kbytes/sec] received
$ ab -c 200 -t 60 http://192.168.6.131:3000/buffer

在 HTTP 传输中传输的是二进制数据,上面例子中的 /string 接口直接返回的字符串,这时候 HTTP 在传输之前会先将字符串转换为 Buffer 类型,以二进制数据传输,通过流(Stream)的方式一点点返回到客户端。但是直接返回 Buffer 类型,则少了每次的转换操作,对于性能也是有提升的。
在一些 Web 应用中,对于静态数据可以预先转为 Buffer 进行传输,可以有效减少 CPU 的重复使用(重复的字符串转 Buffer 操作)。
Reference
- http://nodejs.cn/api/buffer.html
- 深入浅出 Node.js Buffer
- Do you want a better understanding of Buffer in Node.js? Check this out.
- A cartoon intro to ArrayBuffers and SharedArrayBuffers
- buffer.js v10.x
Babel、webpack、Vite 等
前言
基于现在JS这门语言快速发展的现状,很多还处于TC39 提案的新语法,或者已经写入新的语言规则的语法提案但在浏览器的支持度上不是十分普及, 以及JS的运行环境,也就是用户的浏览器碎片化的分布,无法保证我们在开发过程中写的JS代码在客户端一致正常的运行,这种情况肯定是不能接受的。
而这正是Babel存在的价值,Babel可以把新的语法编译成能在不同浏览器中运行一致的兼容语法。开发者可以尽情的享受新的语法在开发中带来的爽快,如使用React的jsx语法,ES6的模块方案,class,箭头函数等,而在生产环境中只需要按照需求,配置好Babel的presets和plugins等配置,把项目代码编译成生产代码就可以了。
因此了解一些Babel插件的编写方法绝对是有必要的。
需求
通常,我们使用Babel是在node的环境下,在项目代码运行前就按照一定的配置将代码编译打包好,但这次需要在客户端实时的将用户输入的代码编译成可运行的代码,而其中有一类代码是模块引入的代 码,代码编译成浏览器端的属性读取代码, 例如:
import { prop } from 'modules';
编译成
var { prop } = window['modules'];
因此就需要用一个插件来执行这种编译操作;
实现方式
- 通过Google的 (CDN)[https://unpkg.com/] ,在页面的script标签中加载Babel包,如下 :
<script src="https://unpkg.com/@babel/standalone/babel.min.js"></script>
这样在浏览器的window全局对象里,就会注册一个Babel对象,在这个对象中,有包含transform(编译)、registerPlugin(注册插件)、registerPreset(注册preset)等方法,而在这个需求中,所需要的就是 transform 和 registerPlugin 两个方法了。
- 接下来就是在Babel里面注册一个插件,主要功能是在 Visitors(访问者)“进入”一个节点时,如果是“ImportDeclaration“节点,即引入包的语法,将会进行处理,将该语句替换成属性读取的方式。代码如下:
Babel.registerPlugin("babel-module", function (babel) {
var t = babel.types; // AST模块
return {
visitor: {
ImportDeclaration(path) {
const { node } = path;
const {
objectPattern,
objectProperty,
variableDeclaration,
variableDeclarator
} = t;
var specifiers = node.specifiers.filter(
specifier => specifier.type === "ImportSpecifier"
);
var memberExp = t.memberExpression(
t.identifier("window"),
node.source,
true
); // 成员表达式
var varDeclare = variableDeclaration("var", [
variableDeclarator(
objectPattern(
specifiers.map(specifier =>
objectProperty(
specifier.local,
specifier.local,
false,
true
)
)
),
memberExp
)
]);
path.replaceWith(varDeclare);
}
}
};
});
- 注册完插件后,就可以利于用Babel里的transform方法和刚才的插件,来进行编译了,除了注册的插件以外,还可以利用babel内置的其他插件和preset,如下:
window.Babel.transform(sourceCode, {
presets: ['react'],
plugins: ['babel-module', 'proposal-class-properties'],
ast: true,
}).code
注意:plugins和presets的执行顺序
- plugin在preset前执行
- plugin是从前到后依次执行,即写在前面的先执行
- preset是从后到前依次执行,即写在后面的先执行
- 这样就完成了一个在客户端注册babel插件的过程,在项目中使用自定义的Babel插件方式大同小异,在配置中加上presets和plugins的参数就可以了,参数可以是npm包的名字,也可以是本地文件的相对或者绝对路径,具体参考Babel文档中的 pulgins/presets Path
参考资料
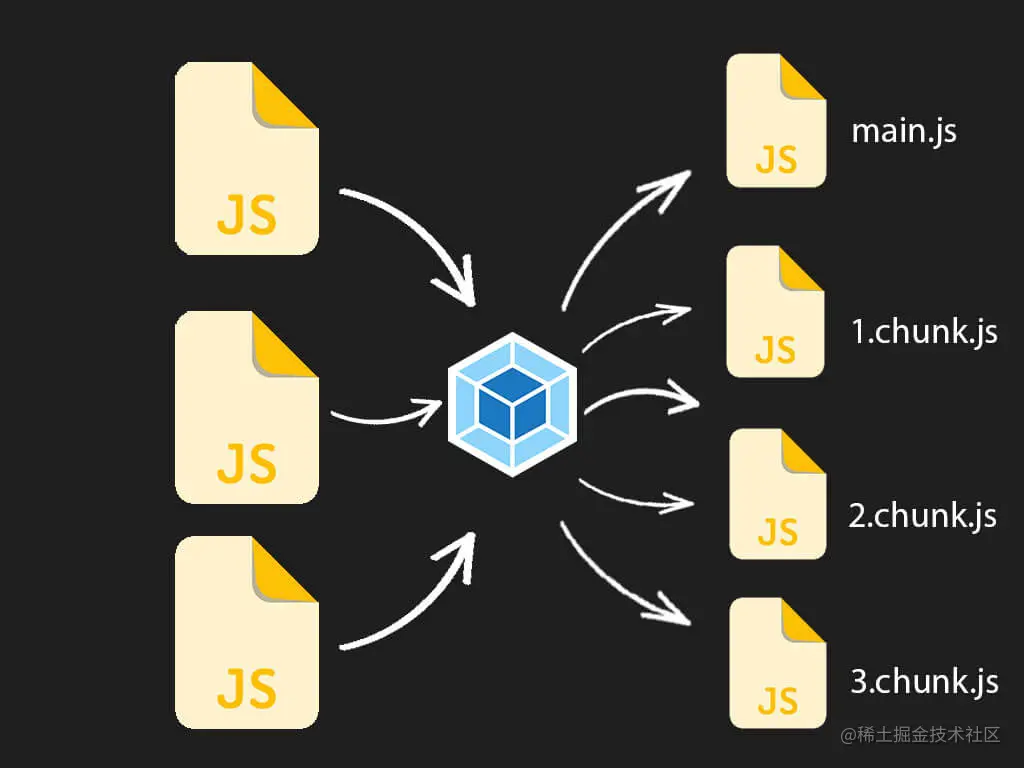
一、前言
在默认的配置情况下,我们知道,webpack 会把所有代码打包到一个 chunk 中,举个例子当你的一个单页面应用很大的时候,你可能就需要将每个路由拆分到一个 chunk 中,这样才方便我们实现按需加载。
代码分离是 webpack 中最引人注目的特性之一。此特性能够把代码分离到不同的 bundle 中,然后可以按需加载或并行加载这些文件。代码分离可以用于获取更小的 bundle,以及控制资源加载优先级,如果使用合理,会极大影响加载时间。
二、关于代码分割
接下来我们会分别分析不同的代码分隔方式带来的打包差异,首先我们的项目假设有这两个简单的文件👇 index.js
import { mul } from './test'
import $ from 'jquery'
console.log($)
console.log(mul(2, 3))
test.js
import $ from 'jquery'
console.log($)
function mul(a, b) {
return a * b
}
export { mul }
可以看到现在他们二者都依赖于 jquery 这个库,并且相互之间也会有依赖。

当我们在默认配置的情况下进行打包,结果是这样的👇,会把所有内容打包进一个 main bundle 内(324kb)


那么我们如何用最直接的方式从这个 bundle 中分离出其他模块呢?
1. 多入口
webpack 配置中的 entry ,可以设置为多个,也就是说我们可以分别将 index 和 test 文件分别作为入口:
// entry: './src/index.js', 原来的单入口
/** 现在分别将它们作为入口 */
entry:{
index:'./src/index.js',
test:'./src/test.js'
},
output: {
filename: '[name].[hash:8].js',
path: path.resolve(__dirname, './dist'),
},
这样让我们看一下这样打包后的结果:

确实打包出了两个文件!但是为什么两个文件都有 320+kb 呢?不是说好拆分获取更小的 bundle ?这是因为由于二者都引入了 jquery 而 webpack 从两次入口进行打包分析的时候会每次都将依赖的模块分别打包进去👇

没错,这种配置的方式确实会带来一些隐患以及不便:
- 如果入口 chunk 之间包含一些重复的模块,那些重复模块都会被引入到各个 bundle 中。
- 这种方法不够灵活,并且不能动态地将核心应用程序逻辑中的代码拆分出来。
那么有没有方式可以既可以将共同依赖的模块进行打包分离,又不用进行繁琐的手动配置入口的方式呢?那必然是有的。
2. SplitChunksPlugin
SplitChunks 是 webpack4 开始自带的开箱即用的一个插件,他可以将满足规则的 chunk 进行分离,也可以自定义配置。在 webpack4 中用它取代了之前用来解决重复依赖的 CommonsChunkPlugin 。 让我们在我们的 webpack 配置中加上一些配置:
entry: './src/index.js', // 这里我们改回单入口
/** 加上如下设置 */
optimization: {
splitChunks: {
chunks: 'all',
},
},
打包后的结果如图:

可以看到很明显除了根据入口打包出的 main bundle 之外,还多出了一个名为 vendors-node_modules_jquery_dist_jquery_js.xxxxx.js ,显然这样我们将公用的 jquery 模块就提取出来了。 接下来我们来探究一下 SplitChunksPlugin 。 首先看下配置的默认值:
splitChunks: {
// 表示选择哪些 chunks 进行分割,可选值有:async,initial 和 all
chunks: "async",
// 表示新分离出的 chunk 必须大于等于 minSize,20000,约 20kb。
minSize: 20000,
// 通过确保拆分后剩余的最小 chunk 体积超过限制来避免大小为零的模块,仅在剩余单个 chunk 时生效
minRemainingSize: 0,
// 表示一个模块至少应被 minChunks 个 chunk 所包含才能分割。默认为 1。
minChunks: 1,
// 表示按需加载文件时,并行请求的最大数目。
maxAsyncRequests: 30,
// 表示加载入口文件时,并行请求的最大数目。
maxInitialRequests: 30,
// 强制执行拆分的体积阈值和其他限制(minRemainingSize,maxAsyncRequests,maxInitialRequests)将被忽略
enforceSizeThreshold: 50000,
// cacheGroups 下可以可以配置多个组,每个组根据 test 设置条件,符合 test 条件的模块,就分配到该组。模块可以被多个组引用,但最终会根据 priority 来决定打包到哪个组中。默认将所有来自 node_modules 目录的模块打包至 vendors 组,将两个以上的 chunk 所共享的模块打包至 default 组。
cacheGroups: {
defaultVendors: {
test: /[\\/]node_modules[\\/]/,
// 一个模块可以属于多个缓存组。优化将优先考虑具有更高 priority(优先级)的缓存组。
priority: -10,
// 如果当前 chunk 包含已从主 bundle 中拆分出的模块,则它将被重用
reuseExistingChunk: true,
},
default: {
minChunks: 2,
priority: -20,
reuseExistingChunk: true
}
}
}
默认情况下,SplitChunks 只会对异步调用的模块进行分割(chunks: “async”),并且默认情况下处理的 chunk 至少要有 20kb ,过小的模块不会被包含进去。
补充一下,默认值会根据 mode 的配置不同有所变化,具体参见源码👇:
const { splitChunks } = optimization;
if (splitChunks) {
A(splitChunks, "defaultSizeTypes", () => ["javascript", "unknown"]);
D(splitChunks, "hidePathInfo", production);
D(splitChunks, "chunks", "async");
D(splitChunks, "usedExports", optimization.usedExports === true);
D(splitChunks, "minChunks", 1);
F(splitChunks, "minSize", () => (production ? 20000 : 10000));
F(splitChunks, "minRemainingSize", () => (development ? 0 : undefined));
F(splitChunks, "enforceSizeThreshold", () => (production ? 50000 : 30000));
F(splitChunks, "maxAsyncRequests", () => (production ? 30 : Infinity));
F(splitChunks, "maxInitialRequests", () => (production ? 30 : Infinity));
D(splitChunks, "automaticNameDelimiter", "-");
const { cacheGroups } = splitChunks;
F(cacheGroups, "default", () => ({
idHint: "",
reuseExistingChunk: true,
minChunks: 2,
priority: -20
}));
F(cacheGroups, "defaultVendors", () => ({
idHint: "vendors",
reuseExistingChunk: true,
test: NODE_MODULES_REGEXP,
priority: -10
}));
}
cacheGroups 缓存组是施行分割的重中之重,他可以使用来自 splitChunks.* 的任何选项,但是 test、priority 和 reuseExistingChunk 只能在缓存组级别上进行配置。默认配置中已经给我们提供了 Vendors 组和一个 defalut 组,Vendors组中使用 test: /[\\/]node_modules[\\/]/ 匹配了 node_modules 中的所有符合规则的模块。
Tip:当 webpack 处理文件路径时,它们始终包含 Unix 系统中的 / 和 Windows 系统中的 \。这就是为什么在 {cacheGroup}.test 字段中使用 [\\/] 来表示路径分隔符的原因。{cacheGroup}.test 中的 / 或 \ 会在跨平台使用时产生问题。
综上的配置,我们便可以理解为什么我们在打包中会产生出名为 vendors-node_modules_jquery_dist_jquery_js.db47cc72.js 的文件了。如果你想要对名称进行自定义的话,也可以使用 splitChunks.name 属性(每个 cacheGroup 中都可以使用),这个属性支持使用三种形式:
- boolean = false 设为 false 将保持 chunk 的相同名称,因此不会不必要地更改名称。这是生产环境下构建的建议值。
- function (module, chunks, cacheGroupKey) => string 返回值要求是 string 类型,并且在 chunks 数组中每一个 chunk 都有 chunk.name 和 chunk.hash 属性,举个例子 👇
name(module, chunks, cacheGroupKey) {
const moduleFileName = module
.identifier()
.split('/')
.reduceRight((item) => item);
const allChunksNames = chunks.map((item) => item.name).join('~');
return `${cacheGroupKey}-${allChunksNames}-${moduleFileName}`;
},
- string 指定字符串或始终返回相同字符串的函数会将所有常见模块和 vendor 合并为一个 chunk。这可能会导致更大的初始下载量并减慢页面加载速度。
另外注意一下 splitChunks.maxAsyncRequests 和 splitChunks.maxInitialRequests 分别指的是按需加载时最大的并行请求数和页面初始渲染时候需要的最大并行请求数 在我们的项目较大时,如果需要对某个依赖单独拆包的话,可以进行这样的配置:
cacheGroups: {
react: {
name: 'react',
test: /[\\/]node_modules[\\/](react)/,
chunks: 'all',
priority: -5,
},
},
这样打包后就可以拆分指定的包:

更多配置详见官网配置文档
3. 动态 import
使用 import() 语法 来实现动态导入也是我们非常推荐的一种代码分割的方式,我们先来简单修改一下我们的 index.js ,再来看一下使用后打包的效果:
// import { mul } from './test'
import $ from 'jquery'
import('./test').then(({ mul }) => {
console.log(mul(2,3))
})
console.log($)
// console.log(mul(2, 3))
可以看到,通过 import() 语法导入的模块在打包时会自动单独进行打包
值得注意的是,这种语法还有一种很方便的“动态引用”的方式,他可以加入一些适当的表达式,举个例子,假设我们需要加载适当的主题:
const themeType = getUserTheme();
import(`./themes/${themeType}`).then((module) => {
// do sth aboout theme
});
这样我们就可以“动态”加载我们需要的异步模块,实现的原理主要在于两点:
- 至少需要包含模块相关的路径信息,打包可以限定于一个特定的目录或文件集。
- 根据路径信息 webpack 在打包时会把 ./themes 中的所有文件打包进新的 chunk 中,以便需要时使用到。
4. 魔术注释
在上述的 import() 语法中,我们会发现打包自动生成的文件名并不是我们想要的,我们如何才能自己控制打包的名称呢?这里就要引入我们的魔术注释(Magic Comments):
import(/* webpackChunkName: "my-chunk-name" */'./test')
通过这样打包出来的文件:
魔术注释不仅仅可以帮我们修改 chunk 名这么简单,他还可以实现譬如预加载等功能,这里举个例子: 我们通过希望在点击按钮时才加载我们需要的模块功能,代码可以这样:
// index.js
document.querySelector('#btn').onclick = function () {
import('./test').then(({ mul }) => {
console.log(mul(2, 3));
});
};
//test.js
function mul(a, b) {
return a * b;
}
console.log('test 被加载了');
export { mul };
可以看到,在我们点击按钮的同时确实加载了 test.js 的文件资源。但是如果这个模块是一个很大的模块,在点击时进行加载可能会造成长时间 loading 等用户体验不是很好的效果,这个时候我们可以使用我们的 /* webpackPrefetch: true */ 方式进行预获取,来看下效果:
// index,js
document.querySelector('#btn').onclick = function () {
import(/* webpackPrefetch: true */'./test').then(({ mul }) => {
console.log(mul(2, 3));
});
};
可以看到整个过程中,在画面初始加载的时候,test.js 的资源就已经被预先加载了,而在我们点击按钮时,会从 (prefetch cache) 中读取内容。这就是模块预获取的过程。另外我们还有 / webpackPreload: true / 的方式进行预加载。 但是 prefetch 和 preload 听起来感觉差不多,实际上他们的加载时机等是完全不同的:
- preload chunk 会在父 chunk 加载时,以并行方式开始加载。prefetch chunk 会在父 chunk 加载结束后开始加载。
- preload chunk 具有中等优先级,并立即下载。prefetch chunk 在浏览器闲置时下载。
- preload chunk 会在父 chunk 中立即请求,用于当下时刻。prefetch chunk 会用于未来的某个时刻。
三、结尾
在最初有工程化打包思想时,我们会考虑将多文件打包到一个文件内减少多次的资源请求,随着项目的越来越复杂,做项目优化时,我们发现项目加载越久用户体验就越不好,于是又可以通过代码分割的方式去减少页面初加载时的请求过大的资源体积。 本文中仅简单介绍了常用的 webpack 代码分割方式,但是在实际的项目中进行性能优化时,往往会有更加严苛的要求,希望可以通过本文的介绍让大家快速了解上手代码分割的技巧与优势。
网络协议
HTTP 缓存机制
一、 两种缓存规则
强制缓存的优先级高于协商缓存,当执行强制缓存时,如若缓存命中,则直接使用缓存数据库数据,不在进行缓存协商。
1.1 强制缓存
当缓存数据库中已有所请求的数据时。客户端直接从缓存数据库中获取数据。当缓存数据库中没有所请求的数据时,客户端的才会从服务端获取数据。
1.1.1 浏览器实现
对于强制缓存,服务器响应的 header 中会用两个字段来表明—— Expires 和 Cache-Control。
1.1.2 Expires
Exprires的值为服务端返回的数据到期时间。当再次请求时的请求时间小于返回的此时间,则直接使用缓存数据。但由于服务端时间和客户端时间可能有误差,这也将导致缓存命中的误差,另一方面,Expires是HTTP1.0的产物,故现在大多数使用 Cache-Control 替代。
1.1.3 Cache-Control
Cache-Control有很多属性,不同的属性代表的意义也不同: - private:客户端可以缓存; - public:客户端和代理服务器都可以缓存 - max-age=t:缓存内容将在t秒后失效 - no-cache:需要使用协商缓存来验证缓存数据 - no-store:所有内容都不会缓存。 - must-revalidate:
1.2 协商缓存
又称对比缓存,客户端会先从缓存数据库中获取到一个缓存数据的标识,得到标识后请求服务端验证是否失效(新鲜),如果没有失效服务端会返回304,此时客户端直接从缓存中获取所请求的数据,如果标识失效,服务端会返回更新后的数据。
有两种缓存方案
1.2.1 Last-Modified
服务器在响应请求时,会告诉浏览器资源的最后修改时间。
if-Modified-Since: 浏览器再次请求服务器的时候,请求头会包含此字段,后面跟着在缓存中获得的最后修改时间。服务端收到此请求头发现有if-Modified-Since,则与被请求资源的最后修改时间进行对比,如果一致则返回304和响应报文头,浏览器只需要从缓存中获取信息即可。 从字面上看,就是说:从某个时间节点算起,是否文件被修改了
如果真的被修改:那么开始传输响应一个整体,服务器返回:200 OK
如果没有被修改:那么只需传输响应header,服务器返回:304 Not Modified
if-Unmodified-Since: 从字面上看, 就是说: 从某个时间点算起, 是否文件没有被修改
如果没有被修改:则开始`继续'传送文件: 服务器返回: 200 OK
如果文件被修改:则不传输,服务器返回: 412 Precondition failed (预处理错误)
这两个的区别是一个是修改了才下载一个是没修改才下载。
Last-Modified 说好却也不是特别好,因为如果在服务器上,一个资源被修改了,但其实际内容根本没发生改变,会因为Last-Modified时间匹配不上而返回了整个实体给客户端(即使客户端缓存里有个一模一样的资源)。为了解决这个问题,HTTP1.1推出了 Etag。
1.2.2 Etag
Etag: 服务器响应请求时,通过此字段告诉浏览器当前资源在服务器生成的唯一标识(生成规则由服务器决定);
If-None-Match: 再次请求服务器时,浏览器的请求报文头部会包含此字段,后面的值为在缓存中获取的标识。服务器接收到次报文后发现If-None-Match则与被请求资源的唯一标识进行对比:
- 不同,说明资源被改动过,则响应整个资源内容,返回状态码200。
- 相同,说明资源无新修改,则响应header,浏览器直接从缓存中获取数据信息。返回状态码304.
参考文档:
HTTPS
服务器端生成数字证书
- 生成本地密钥对;
- 发送公钥和其他基本信息到 CA认证中心 生成数据证书;
CA 认证中心:
-
采用单向hash算法对公钥和基本信息进行摘要算法;
-
用私匙对摘要进行加密,生成数字签名;
-
将申请信息(包含服务器的公匙)和数字签名整合在一起,生成数字证书;
-
返回数字证书;
使用数字证书 协商对称加密密钥
-
server 将数字证书发送个 client;
-
client 通过 CA 公钥解密出摘要信息,并用相同的 hash 算法对 sever 的申请信息生成摘要,比对摘要信息。
-
如果相同则说明内容完整,没有被篡改, client 使用公钥加密生成的对称密钥;
-
server 使用私钥解密 client 的密文,得到对称加密密钥;
-
server 和 client 使用对称加密的方式进行后续通信;
为何不能被窃听和篡改
- 不能窃听
攻击者截获 client 使用公钥加密生成的对称密钥,因为没有 server 的私钥,所以无法解密出对称密钥;
- 不能篡改
攻击者截获 server 的数字证书,可以通过 CA 公钥解密出摘要信息和 server 的公钥,但没有 CA 的私钥,所以无法重新篡改报文。
HTTP/1 和 HTTP/2
一、三次握手讲解
- 客户端发送位码为syn=1,随机产生seq number=x 的数据包到服务器,服务器由SYN=1知道客户端要求建立联机(客户端:我要连接你)
- 服务器收到请求后要确认联机信息,向A发送ack number= x+1 (客户端的seq+1),syn=1,ack=1,随机产生seq=7654321的包(服务器:好的,你来连吧)
- 客户端收到后检查ack number是否正确,即第一次发送的seq number+1,以及位码ack是否为1,若正确,客户端会再发送ack number=(服务器的seq+1),ack=1,服务器收到后确认seq值与ack=1则连接建立成功。(客户端:好的,我来了)
二、为什么http建立连接需要三次握手,不是两次或四次?
答:三次是最少的安全次数,两次不安全,四次浪费资源;
三、TCP关闭连接过程
-
Client向Server发送FIN包,表示Client主动要关闭连接,然后进入FIN_WAIT_1状态,等待Server返回ACK包。此后Client不能再向Server发送数据,但能读取数据。
-
Server收到FIN包后向Client发送ACK包,然后进入CLOSE_WAIT状态,此后Server不能再读取数据,但可以继续向Client发送数据。
-
Client收到Server返回的ACK包后进入FIN_WAIT_2状态,等待Server发送FIN包。
-
Server完成数据的发送后,将FIN包发送给Client,然后进入LAST_ACK状态,等待Client返回ACK包,此后Server既不能读取数据,也不能发送数据。
-
Client收到FIN包后向Server发送ACK包,然后进入TIME_WAIT状态,接着等待足够长的时间(2MSL)以确保Server接收到ACK包,最后回到CLOSED状态,释放网络资源。
-
Server收到Client返回的ACK包后便回到CLOSED状态,释放网络资源。
四、为什么要四次挥手?
TCP是全双工信道,何为全双工?就是客户端与服务端建立两条通道,通道1:客户端的输出连接服务端的输入;通道2:客户端的输入连接服务端的输出。两个通道可以同时工作:客户端向服务端发送信号的同时服务端也可以向客户端发送信号。所以关闭双通道的时候就是这样:
客户端:我要关闭输入通道了。 服务端:好的,你关闭吧,我这边也关闭这个通道。
服务端:我也要关闭输入通道了。 客户端:好的你关闭吧,我也把这个通道关闭。
HTTP/1
在 HTTP/1 中,每次请求都会建立一次HTTP连接,也就是我们常说的3次握手4次挥手,这个过程在一次请求过程中占用了相当长的时间,即使开启了 Keep-Alive ,解决了多次连接的问题,但是依然有两个效率上的问题:
-
第一个:串行的文件传输。当请求a文件时,b文件只能等待,等待a连接到服务器、服务器处理文件、服务器返回文件,这三个步骤。我们假设这三步用时都是1秒,那么a文件用时为3秒,b文件传输完成用时为6秒,依此类推。(注:此项计算有一个前提条件,就是浏览器和服务器是单通道传输)
-
第二个:连接数过多。我们假设Apache设置了最大并发数为300,因为浏览器限制,浏览器发起的最大请求数为6,也就是服务器能承载的最高并发为50,当第51个人访问时,就需要等待前面某个请求处理完成。
HTTP/2
HTTP/2的多路复用就是为了解决上述的两个性能问题。
在 HTTP/2 中,有两个非常重要的概念,分别是帧(frame)和流(stream)。
帧代表着最小的数据单位,每个帧会标识出该帧属于哪个流,流也就是多个帧组成的数据流。
多路复用,就是在一个 TCP 连接中可以存在多条流。换句话说,也就是可以发送多个请求,对端可以通过帧中的标识知道属于哪个请求。通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极大的提高传输性能。
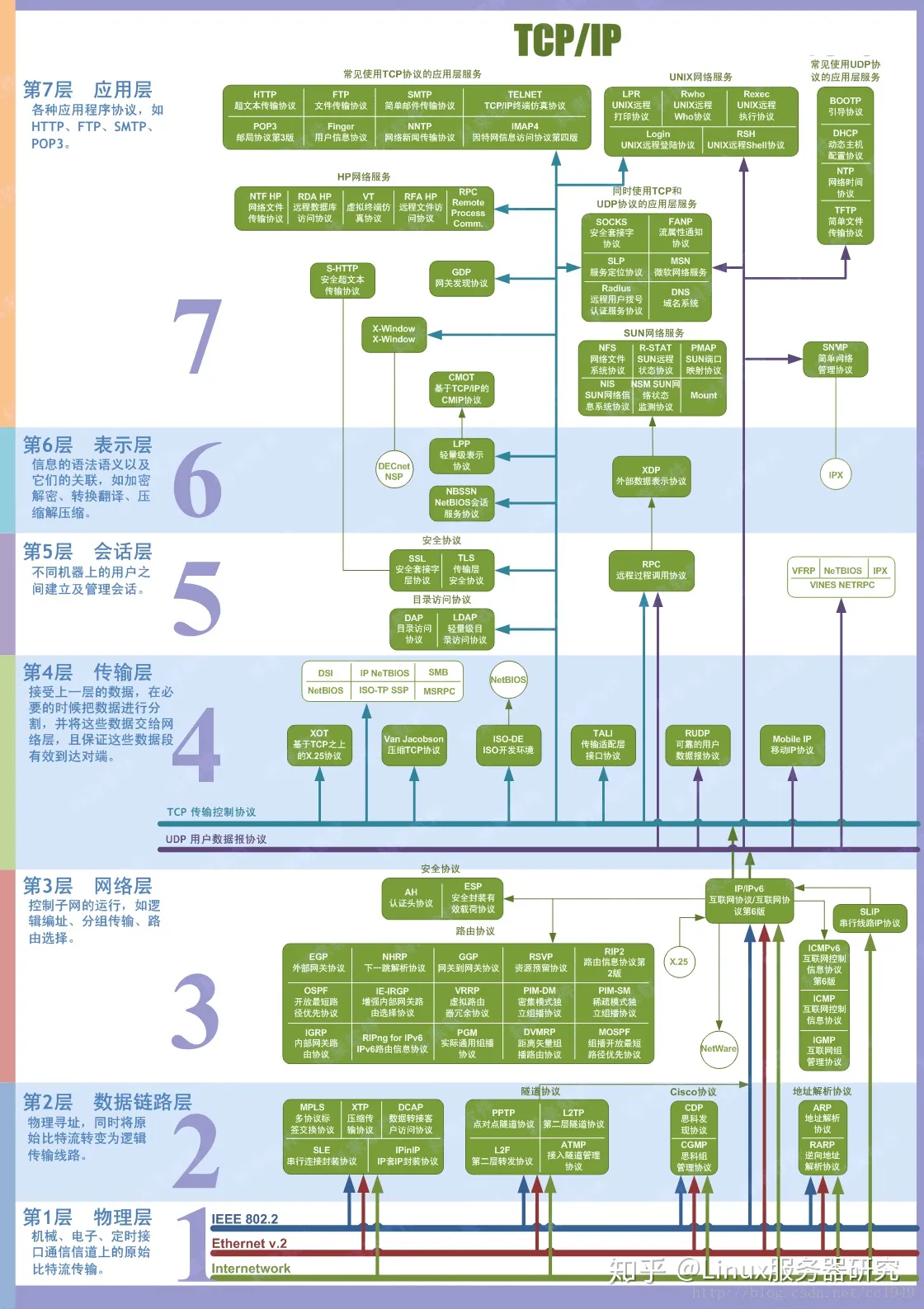
1. OSI 七层模型
OSI是Open System Interconnect的缩写,意为开放式系统互联。
应表会传网数物
7层是指OSI七层协议模型,主要是:应用层(Application)、表示层(Presentation)、会话层(Session)、传输层(Transport)、网络层(Network)、数据链路层(Data Link)、物理层(Physical)。
2. TCP/IP四层模型
4层是指TCP/IP四层模型,主要包括:应用层、运输层、网际层和网络接口层。
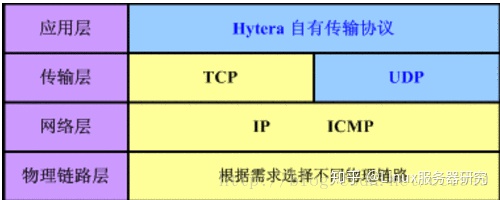
4层协议和对应的标准7层协议的关系如下图:
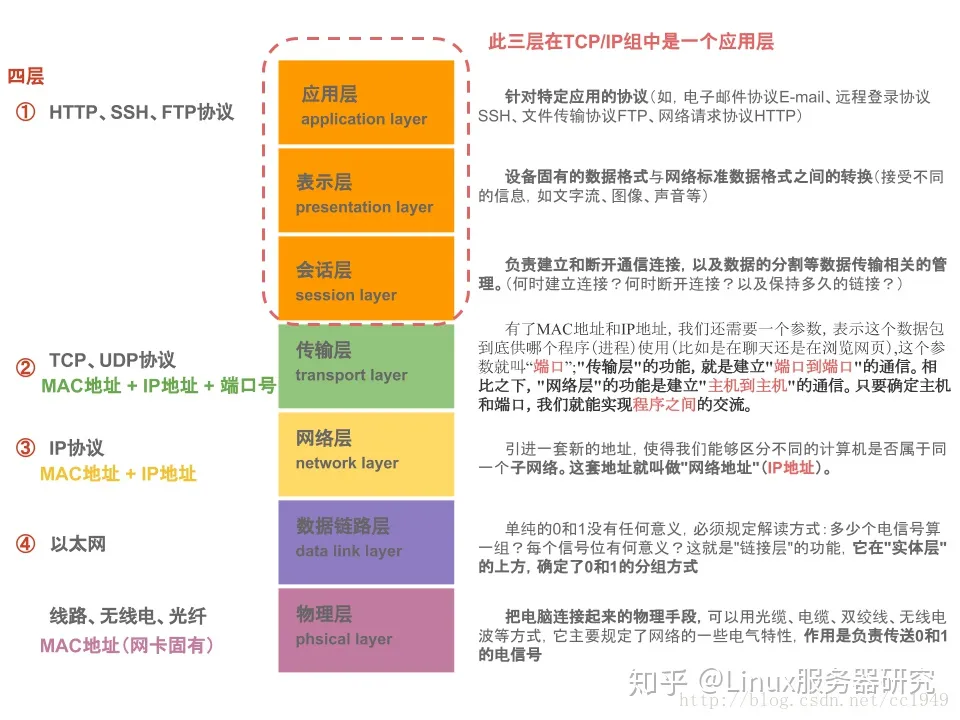
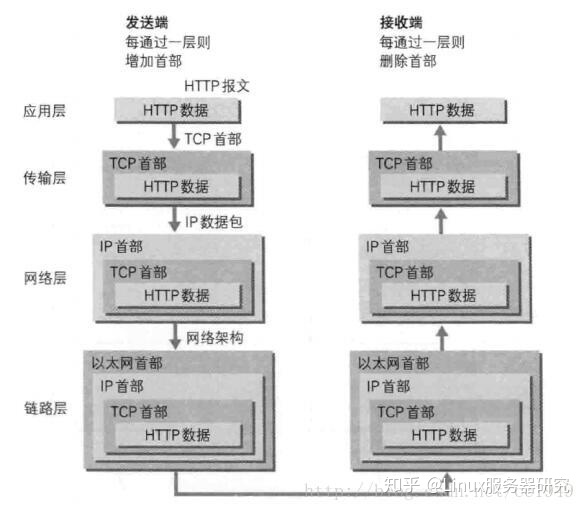
从上往下,每经过一层,协议就会在数据包包头上面做点手脚,加点东西,传送到接收端,再层层解套出来,如下示意图:
3. TCP和UDP的区别
1、基于连接与无连接;
TCP 是面向连接的协议,在收发数据前必须和对方建立可靠的连接,一个TCP连接必须要经过三次“对话”才能建立起来; UDP 是一个非连接的协议,传输数据之前源端和终端不建立连接, 当它想传送时就简单地去抓取来自应用程序的数据,并尽可能快地把它扔到网络上。 在发送端,UDP传送数据的速度仅仅是受应用程序生成数据的速度、 计算机的能力和传输带宽的限制; 在接收端,UDP把每个消息段放在队列中,应用程序每次从队列中读一个消息段。
2、对系统资源的要求(TCP较多,UDP少);
3、UDP程序结构较简单;
4、流模式与数据报模式 ;
udp面向数据报,每次传输都是一个一个数据包交付,不合并也不拆分,向下向上只是加首部和去首部的区别; tcp是面向字节流的,简单说就是,应用程序和tcp交互每次一个数据块,但tcp只把这些看做是字节流,它不保证接受方收到的数据快的大小和发送方一样,比如发送方发了10个数据块给tcp但是但接收方的tcp可能只用了5个数据块就把收到的字节流交付给自己上方的应用程序了。 总:只保证字节流大小一致,不保证数据块。因为tcp发送时要考虑对方给出的窗口值和网络拥塞情况界定发送的块的大小,言简意赅就是:大了我分块发送,少了我可以累积在一起在发送。保证你接收方收到的字节流和发送方发出的字节流一样就行。 5、TCP保证数据正确性,UDP可能丢包;
6、TCP保证数据顺序,UDP不保证。
设计模式简介
设计模式原则
- S – Single Responsibility Principle 单一职责原则
- 一个程序只做好一件事
- 如果功能过于复杂就拆分开,每个部分保持独立
- O – OpenClosed Principle 开放/封闭原则
- 对扩展开放,对修改封闭
- 增加需求时,扩展新代码,而非修改已有代码
- L – Liskov Substitution Principle 里氏替换原则
- 子类能覆盖父类
- 父类能出现的地方子类就能出现
- I – Interface Segregation Principle 接口隔离原则
- 保持接口的单一独立
- 类似单一职责原则,这里更关注接口
- D – Dependency Inversion Principle 依赖倒转原则
- 面向接口编程,依赖于抽象而不依赖于具体
- 使用方只关注接口而不关注具体类的实现
设计模式分类(23种设计模式)
- 创建型
- 单例模式
- 原型模式
- 工厂模式
- 抽象工厂模式
- 建造者模式
- 结构型
- 适配器模式
- 装饰器模式
- 代理模式
- 外观模式
- 桥接模式
- 组合模式
- 享元模式
- 行为型
- 观察者模式
- 迭代器模式
- 策略模式
- 模板方法模式
- 职责链模式
- 命令模式
- 备忘录模式
- 状态模式
- 访问者模式
- 中介者模式
- 解释器模式
工厂模式
工厂模式定义一个用于创建对象的接口,这个接口由子类决定实例化哪一个类。该模式使一个类的实例化延迟到了子类。而子类可以重写接口方法以便创建的时候指定自己的对象类型。
class Product {
constructor(name) {
this.name = name
}
init() {
console.log('init')
}
fun() {
console.log('fun')
}
}
class Factory {
create(name) {
return new Product(name)
}
}
// use
let factory = new Factory()
let p = factory.create('p1')
p.init()
p.fun()
适用场景
- 如果你不想让某个子系统与较大的那个对象之间形成强耦合,而是想运行时从许多子系统中进行挑选的话,那么工厂模式是一个理想的选择
- 将new操作简单封装,遇到new的时候就应该考虑是否用工厂模式;
- 需要依赖具体环境创建不同实例,这些实例都有相同的行为,这时候我们可以使用工厂模式,简化实现的过程,同时也可以减少每种对象所需的代码量,有利于消除对象间的耦合,提供更大的灵活性
优点
- 创建对象的过程可能很复杂,但我们只需要关心创建结果。
- 构造函数和创建者分离, 符合“开闭原则”
- 一个调用者想创建一个对象,只要知道其名称就可以了。
- 扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以。
缺点
添加新产品时,需要编写新的具体产品类,一定程度上增加了系统的复杂度 考虑到系统的可扩展性,需要引入抽象层,在客户端代码中均使用抽象层进行定义,增加了系统的抽象性和理解难度
什么时候不用
当被应用到错误的问题类型上时,这一模式会给应用程序引入大量不必要的复杂性.除非为创建对象提供一个接口是我们编写的库或者框架的一个设计上目标,否则我会建议使用明确的构造器,以避免不必要的开销。 由于对象的创建过程被高效的抽象在一个接口后面的事实,这也会给依赖于这个过程可能会有多复杂的单元测试带来问题。
例子
- 曾经我们熟悉的JQuery的$()就是一个工厂函数,它根据传入参数的不同创建元素或者去寻找上下文中的元素,创建成相应的jQuery对象
class jQuery {
constructor(selector) {
super(selector)
}
add() {
}
// 此处省略若干API
}
window.$ = function(selector) {
return new jQuery(selector)
}
- vue 的异步组件
在大型应用中,我们可能需要将应用分割成小一些的代码块,并且只在需要的时候才从服务器加载一个模块。为了简化,Vue 允许你以一个工厂函数的方式定义你的组件,这个工厂函数会异步解析你的组件定义。Vue 只有在这个组件需要被渲染的时候才会触发该工厂函数,且会把结果缓存起来供未来重渲染。例如:
Vue.component('async-example', function (resolve, reject) {
setTimeout(function () {
// 向 `resolve` 回调传递组件定义
resolve({
template: '<div>I am async!</div>'
})
}, 1000)
})
单例模式
一个类只有一个实例,并提供一个访问它的全局访问点。
class LoginForm {
constructor() {
this.state = 'hide'
}
show() {
if (this.state === 'show') {
alert('已经显示')
return
}
this.state = 'show'
console.log('登录框显示成功')
}
hide() {
if (this.state === 'hide') {
alert('已经隐藏')
return
}
this.state = 'hide'
console.log('登录框隐藏成功')
}
}
LoginForm.getInstance = (function () {
let instance
return function () {
if (!instance) {
instance = new LoginForm()
}
return instance
}
})()
let obj1 = LoginForm.getInstance()
obj1.show()
let obj2 = LoginForm.getInstance()
obj2.hide()
console.log(obj1 === obj2)
优点
- 划分命名空间,减少全局变量
- 增强模块性,把自己的代码组织在一个全局变量名下,放在单一位置,便于维护
- 且只会实例化一次。简化了代码的调试和维护
缺点
- 由于单例模式提供的是一种单点访问,所以它有可能导致模块间的强耦合 从而不利于单元测试。无法单独测试一个调用了来自单例的方法的类,而只能把它与那个单例作为一个单元一起测试。
场景例子
定义命名空间和实现分支型方法 登录框 vuex 和 redux中的store
适配器模式
将一个类的接口转化为另外一个接口,以满足用户需求,使类之间接口不兼容问题通过适配器得以解决。
class Plug {
getName() {
return 'iphone充电头';
}
}
class Target {
constructor() {
this.plug = new Plug();
}
getName() {
return this.plug.getName() + ' 适配器Type-c充电头';
}
}
let target = new Target();
target.getName(); // iphone充电头 适配器转Type-c充电头
优点
- 可以让任何两个没有关联的类一起运行。
- 提高了类的复用。
- 适配对象,适配库,适配数据
缺点
- 额外对象的创建,非直接调用,存在一定的开销(且不像代理模式在某些功能点上可实现性能优化)
- 如果没必要使用适配器模式的话,可以考虑重构,如果使用的话,尽量把文档完善
场景
- 整合第三方SDK
- 封装旧接口
// 自己封装的ajax, 使用方式如下
ajax({
url: '/getData',
type: 'Post',
dataType: 'json',
data: {
test: 111
}
}).done(function() {})
// 因为历史原因,代码中全都是:
// $.ajax({....})
// 做一层适配器
var $ = {
ajax: function (options) {
return ajax(options)
}
}
- vue的computed
<template>
<div id="example">
<p>Original message: "{{ message }}"</p> <!-- Hello -->
<p>Computed reversed message: "{{ reversedMessage }}"</p> <!-- olleH -->
</div>
</template>
<script type='text/javascript'>
export default {
name: 'demo',
data() {
return {
message: 'Hello'
}
},
computed: {
reversedMessage: function() {
return this.message.split('').reverse().join('')
}
}
}
</script>
原有data 中的数据不满足当前的要求,通过计算属性的规则来适配成我们需要的格式,对原有数据并没有改变,只改变了原有数据的表现形式
不同点
适配器与代理模式相似
- 适配器模式: 提供一个不同的接口(如不同版本的插头)
- 代理模式: 提供一模一样的接口
装饰者模式
- 动态地给某个对象添加一些额外的职责,,是一种实现继承的替代方案
- 在不改变原对象的基础上,通过对其进行包装扩展,使原有对象可以满足用户的更复杂需求,而不会影响从这个类中派生的其他对象
class Cellphone {
create() {
console.log('生成一个手机')
}
}
class Decorator {
constructor(cellphone) {
this.cellphone = cellphone
}
create() {
this.cellphone.create()
this.createShell(cellphone)
}
createShell() {
console.log('生成手机壳')
}
}
// 测试代码
let cellphone = new Cellphone()
cellphone.create()
console.log('------------')
let dec = new Decorator(cellphone)
dec.create()
场景例子
- 比如现在有4 种型号的自行车,我们为每种自行车都定义了一个单独的类。现在要给每种自行车都装上前灯、尾灯和铃铛这3 种配件。如果使用继承的方式来给每种自行车创建子类,则需要 4×3 = 12 个子类。但是如果把前灯、尾灯、铃铛这些对象动态组合到自行车上面,则只需要额外增加3 个类
- ES7 Decorator 阮一峰
- core-decorators
优点
- 装饰类和被装饰类都只关心自身的核心业务,实现了解耦。
- 方便动态的扩展功能,且提供了比继承更多的灵活性。
缺点
- 多层装饰比较复杂。
- 常常会引入许多小对象,看起来比较相似,实际功能大相径庭,从而使得我们的应用程序架构变得复杂起来
代理模式
是为一个对象提供一个代用品或占位符,以便控制对它的访问
假设当A 在心情好的时候收到花,小明表白成功的几率有 60%,而当A 在心情差的时候收到花,小明表白的成功率无限趋近于0。 小明跟A 刚刚认识两天,还无法辨别A 什么时候心情好。如果不合时宜地把花送给A,花 被直接扔掉的可能性很大,这束花可是小明吃了7 天泡面换来的。 但是A 的朋友B 却很了解A,所以小明只管把花交给B,B 会监听A 的心情变化,然后选 择A 心情好的时候把花转交给A,代码如下:
let Flower = function() {}
let xiaoming = {
sendFlower: function(target) {
let flower = new Flower()
target.receiveFlower(flower)
}
}
let B = {
receiveFlower: function(flower) {
A.listenGoodMood(function() {
A.receiveFlower(flower)
})
}
}
let A = {
receiveFlower: function(flower) {
console.log('收到花'+ flower)
},
listenGoodMood: function(fn) {
setTimeout(function() {
fn()
}, 1000)
}
}
xiaoming.sendFlower(B)
场景
- HTML元 素事件代理
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
<script>
let ul = document.querySelector('#ul');
ul.addEventListener('click', event => {
console.log(event.target);
});
</script>
- ES6 的 proxy 阮一峰Proxy
- jQuery.proxy()方法
优点
- 代理模式能将代理对象与被调用对象分离,降低了系统的耦合度。代理模式在客户端和目标对象之间起到一个中介作用,这样可以起到保护目标对象的作用
- 代理对象可以扩展目标对象的功能;通过修改代理对象就可以了,符合开闭原则;
缺点
处理请求速度可能有差别,非直接访问存在开销
不同点
装饰者模式实现上和代理模式类似
- 装饰者模式: 扩展功能,原有功能不变且可直接使用
- 代理模式: 显示原有功能,但是经过限制之后的
外观模式
为子系统的一组接口提供一个一致的界面,定义了一个高层接口,这个接口使子系统更加容易使用
- 兼容浏览器事件绑定
let addMyEvent = function (el, ev, fn) {
if (el.addEventListener) {
el.addEventListener(ev, fn, false)
} else if (el.attachEvent) {
el.attachEvent('on' + ev, fn)
} else {
el['on' + ev] = fn
}
};
- 封装接口
let myEvent = {
// ...
stop: e => {
e.stopPropagation();
e.preventDefault();
}
};
场景
- 设计初期,应该要有意识地将不同的两个层分离,比如经典的三层结构,在数据访问层和业务逻辑层、业务逻辑层和表示层之间建立外观Facade
- 在开发阶段,子系统往往因为不断的重构演化而变得越来越复杂,增加外观Facade可以提供一个简单的接口,减少他们之间的依赖。
- 在维护一个遗留的大型系统时,可能这个系统已经很难维护了,这时候使用外观Facade也是非常合适的,为系系统开发一个外观Facade类,为设计粗糙和高度复杂的遗留代码提供比较清晰的接口,让新系统和Facade对象交互,Facade与遗留代码交互所有的复杂工作。
参考: 大话设计模式
优点
- 减少系统相互依赖。
- 提高灵活性。
- 提高了安全性
缺点
- 不符合开闭原则,如果要改东西很麻烦,继承重写都不合适。
观察者模式
定义了一种一对多的关系,让多个观察者对象同时监听某一个主题对象,这个主题对象的状态发生变化时就会通知所有的观察者对象,使它们能够自动更新自己,当一个对象的改变需要同时改变其它对象,并且它不知道具体有多少对象需要改变的时候,就应该考虑使用观察者模式。
- 发布 & 订阅
- 一对多
// 主题 保存状态,状态变化之后触发所有观察者对象
class Subject {
constructor() {
this.state = 0
this.observers = []
}
getState() {
return this.state
}
setState(state) {
this.state = state
this.notifyAllObservers()
}
notifyAllObservers() {
this.observers.forEach(observer => {
observer.update()
})
}
attach(observer) {
this.observers.push(observer)
}
}
// 观察者
class Observer {
constructor(name, subject) {
this.name = name
this.subject = subject
this.subject.attach(this)
}
update() {
console.log(`${this.name} update, state: ${this.subject.getState()}`)
}
}
// 测试
let s = new Subject()
let o1 = new Observer('o1', s)
let o2 = new Observer('02', s)
s.setState(12)
场景
- DOM事件
document.body.addEventListener('click', function() {
console.log('hello world!');
});
document.body.click()
- vue 响应式
优点
- 支持简单的广播通信,自动通知所有已经订阅过的对象
- 目标对象与观察者之间的抽象耦合关系能单独扩展以及重用
- 增加了灵活性
- 观察者模式所做的工作就是在解耦,让耦合的双方都依赖于抽象,而不是依赖于具体。从而使得各自的变化都不会影响到另一边的变化。
缺点
过度使用会导致对象与对象之间的联系弱化,会导致程序难以跟踪维护和理解
状态模式
允许一个对象在其内部状态改变的时候改变它的行为,对象看起来似乎修改了它的类
// 状态 (弱光、强光、关灯)
class State {
constructor(state) {
this.state = state
}
handle(context) {
console.log(`this is ${this.state} light`)
context.setState(this)
}
}
class Context {
constructor() {
this.state = null
}
getState() {
return this.state
}
setState(state) {
this.state = state
}
}
// test
let context = new Context()
let weak = new State('weak')
let strong = new State('strong')
let off = new State('off')
// 弱光
weak.handle(context)
console.log(context.getState())
// 强光
strong.handle(context)
console.log(context.getState())
// 关闭
off.handle(context)
console.log(context.getState())
场景
- 一个对象的行为取决于它的状态,并且它必须在运行时刻根据状态改变它的行为
- 一个操作中含有大量的分支语句,而且这些分支语句依赖于该对象的状态
优点
- 定义了状态与行为之间的关系,封装在一个类里,更直观清晰,增改方便
- 状态与状态间,行为与行为间彼此独立互不干扰
- 用对象代替字符串来记录当前状态,使得状态的切换更加一目了然
缺点
- 会在系统中定义许多状态类
- 逻辑分散
迭代器模式
提供一种方法顺序一个聚合对象中各个元素,而又不暴露该对象的内部表示。
class Iterator {
constructor(conatiner) {
this.list = conatiner.list
this.index = 0
}
next() {
if (this.hasNext()) {
return this.list[this.index++]
}
return null
}
hasNext() {
if (this.index >= this.list.length) {
return false
}
return true
}
}
class Container {
constructor(list) {
this.list = list
}
getIterator() {
return new Iterator(this)
}
}
// 测试代码
let container = new Container([1, 2, 3, 4, 5])
let iterator = container.getIterator()
while(iterator.hasNext()) {
console.log(iterator.next())
}
场景例子
- Array.prototype.forEach
- jQuery中的$.each()
- ES6 Iterator
特点
- 访问一个聚合对象的内容而无需暴露它的内部表示。
- 为遍历不同的集合结构提供一个统一的接口,从而支持同样的算法在不同的集合结构上进行操作
总结
对于集合内部结果常常变化各异,不想暴露其内部结构的话,但又想让客户代码透明的访问其中的元素,可以使用迭代器模式
桥接模式
桥接模式(Bridge)将抽象部分与它的实现部分分离,使它们都可以独立地变化。
class Color {
constructor(name){
this.name = name
}
}
class Shape {
constructor(name,color){
this.name = name
this.color = color
}
draw(){
console.log(`${this.color.name} ${this.name}`)
}
}
//测试
let red = new Color('red')
let yellow = new Color('yellow')
let circle = new Shape('circle', red)
circle.draw()
let triangle = new Shape('triangle', yellow)
triangle.draw()
优点
- 有助于独立地管理各组成部分, 把抽象化与实现化解耦
- 提高可扩充性
缺点
- 大量的类将导致开发成本的增加,同时在性能方面可能也会有所减少。
组合模式
- 将对象组合成树形结构,以表示“整体-部分”的层次结构。
- 通过对象的多态表现,使得用户对单个对象和组合对象的使用具有一致性。
class TrainOrder {
create () {
console.log('创建火车票订单')
}
}
class HotelOrder {
create () {
console.log('创建酒店订单')
}
}
class TotalOrder {
constructor () {
this.orderList = []
}
addOrder (order) {
this.orderList.push(order)
return this
}
create () {
this.orderList.forEach(item => {
item.create()
})
return this
}
}
// 可以在购票网站买车票同时也订房间
let train = new TrainOrder()
let hotel = new HotelOrder()
let total = new TotalOrder()
total.addOrder(train).addOrder(hotel).create()
场景
- 表示对象-整体层次结构
- 希望用户忽略组合对象和单个对象的不同,用户将统一地使用组合结构中的所有对象(方法)
缺点
如果通过组合模式创建了太多的对象,那么这些对象可能会让系统负担不起。
原型模式
原型模式(prototype)是指用原型实例指向创建对象的种类,并且通过拷贝这些原型创建新的对象。
class Person {
constructor(name) {
this.name = name
}
getName() {
return this.name
}
}
class Student extends Person {
constructor(name) {
super(name)
}
sayHello() {
console.log(`Hello, My name is ${this.name}`)
}
}
let student = new Student("xiaoming")
student.sayHello()
原型模式,就是创建一个共享的原型,通过拷贝这个原型来创建新的类,用于创建重复的对象,带来性能上的提升。
策略模式
定义一系列的算法,把它们一个个封装起来,并且使它们可以互相替换
<html>
<head>
<title>策略模式-校验表单</title>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type">
</head>
<body>
<form id = "registerForm" method="post" action="http://xxxx.com/api/register">
用户名:<input type="text" name="userName">
密码:<input type="text" name="password">
手机号码:<input type="text" name="phoneNumber">
<button type="submit">提交</button>
</form>
<script type="text/javascript">
// 策略对象
const strategies = {
isNoEmpty: function (value, errorMsg) {
if (value === '') {
return errorMsg;
}
},
isNoSpace: function (value, errorMsg) {
if (value.trim() === '') {
return errorMsg;
}
},
minLength: function (value, length, errorMsg) {
if (value.trim().length < length) {
return errorMsg;
}
},
maxLength: function (value, length, errorMsg) {
if (value.length > length) {
return errorMsg;
}
},
isMobile: function (value, errorMsg) {
if (!/^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|17[7]|18[0|1|2|3|5|6|7|8|9])\d{8}$/.test(value)) {
return errorMsg;
}
}
}
// 验证类
class Validator {
constructor() {
this.cache = []
}
add(dom, rules) {
for(let i = 0, rule; rule = rules[i++];) {
let strategyAry = rule.strategy.split(':')
let errorMsg = rule.errorMsg
this.cache.push(() => {
let strategy = strategyAry.shift()
strategyAry.unshift(dom.value)
strategyAry.push(errorMsg)
return strategies[strategy].apply(dom, strategyAry)
})
}
}
start() {
for(let i = 0, validatorFunc; validatorFunc = this.cache[i++];) {
let errorMsg = validatorFunc()
if (errorMsg) {
return errorMsg
}
}
}
}
// 调用代码
let registerForm = document.getElementById('registerForm')
let validataFunc = function() {
let validator = new Validator()
validator.add(registerForm.userName, [{
strategy: 'isNoEmpty',
errorMsg: '用户名不可为空'
}, {
strategy: 'isNoSpace',
errorMsg: '不允许以空白字符命名'
}, {
strategy: 'minLength:2',
errorMsg: '用户名长度不能小于2位'
}])
validator.add(registerForm.password, [ {
strategy: 'minLength:6',
errorMsg: '密码长度不能小于6位'
}])
validator.add(registerForm.phoneNumber, [{
strategy: 'isMobile',
errorMsg: '请输入正确的手机号码格式'
}])
return validator.start()
}
registerForm.onsubmit = function() {
let errorMsg = validataFunc()
if (errorMsg) {
alert(errorMsg)
return false
}
}
</script>
</body>
</html>
场景例子
- 如果在一个系统里面有许多类,它们之间的区别仅在于它们的’行为’,那么使用策略模式可以动态地让一个对象在许多行为中选择一种行为。
- 一个系统需要动态地在几种算法中选择一种。
- 表单验证
优点
- 利用组合、委托、多态等技术和思想,可以有效的避免多重条件选择语句
- 提供了对开放-封闭原则的完美支持,将算法封装在独立的strategy中,使得它们易于切换,理解,易于扩展
- 利用组合和委托来让Context拥有执行算法的能力,这也是继承的一种更轻便的代替方案
缺点
- 会在程序中增加许多策略类或者策略对象
- 要使用策略模式,必须了解所有的strategy,必须了解各个strategy之间的不同点,这样才能选择一个合适的strategy
享元模式
运用共享技术有效地支持大量细粒度对象的复用。系统只使用少量的对象,而这些对象都很相似,状态变化很小,可以实现对象的多次复用。由于享元模式要求能够共享的对象必须是细粒度对象,因此它又称为轻量级模式,它是一种对象结构型模式
let examCarNum = 0 // 驾考车总数
/* 驾考车对象 */
class ExamCar {
constructor(carType) {
examCarNum++
this.carId = examCarNum
this.carType = carType ? '手动档' : '自动档'
this.usingState = false // 是否正在使用
}
/* 在本车上考试 */
examine(candidateId) {
return new Promise((resolve => {
this.usingState = true
console.log(`考生- ${ candidateId } 开始在${ this.carType }驾考车- ${ this.carId } 上考试`)
setTimeout(() => {
this.usingState = false
console.log(`%c考生- ${ candidateId } 在${ this.carType }驾考车- ${ this.carId } 上考试完毕`, 'color:#f40')
resolve() // 0~2秒后考试完毕
}, Math.random() * 2000)
}))
}
}
/* 手动档汽车对象池 */
ManualExamCarPool = {
_pool: [], // 驾考车对象池
_candidateQueue: [], // 考生队列
/* 注册考生 ID 列表 */
registCandidates(candidateList) {
candidateList.forEach(candidateId => this.registCandidate(candidateId))
},
/* 注册手动档考生 */
registCandidate(candidateId) {
const examCar = this.getManualExamCar() // 找一个未被占用的手动档驾考车
if (examCar) {
examCar.examine(candidateId) // 开始考试,考完了让队列中的下一个考生开始考试
.then(() => {
const nextCandidateId = this._candidateQueue.length && this._candidateQueue.shift()
nextCandidateId && this.registCandidate(nextCandidateId)
})
} else this._candidateQueue.push(candidateId)
},
/* 注册手动档车 */
initManualExamCar(manualExamCarNum) {
for (let i = 1; i <= manualExamCarNum; i++) {
this._pool.push(new ExamCar(true))
}
},
/* 获取状态为未被占用的手动档车 */
getManualExamCar() {
return this._pool.find(car => !car.usingState)
}
}
ManualExamCarPool.initManualExamCar(3) // 一共有3个驾考车
ManualExamCarPool.registCandidates([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) // 10个考生来考试
场景例子
- 文件上传需要创建多个文件实例的时候
- 如果一个应用程序使用了大量的对象,而这些大量的对象造成了很大的存储开销时就应该考虑使用享元模式
优点
- 大大减少对象的创建,降低系统的内存,使效率提高。
缺点
- 提高了系统的复杂度,需要分离出外部状态和内部状态,而且外部状态具有固有化的性质, 不应该随着内部状态的变化而变化,否则会造成系统的混乱
模板方法模式
模板方法模式由两部分结构组成,第一部分是抽象父类,第二部分是具体的实现子类。通常在抽象父类中封装了子类的算法框架,包括实现一些公共方法和封装子类中所有方法的执行顺序。子类通过继承这个抽象类,也继承了整个算法结构,并且可以选择重写父类的方法。
class Beverage {
constructor({brewDrink, addCondiment}) {
this.brewDrink = brewDrink
this.addCondiment = addCondiment
}
/* 烧开水,共用方法 */
boilWater() { console.log('水已经煮沸=== 共用') }
/* 倒杯子里,共用方法 */
pourCup() { console.log('倒进杯子里===共用') }
/* 模板方法 */
init() {
this.boilWater()
this.brewDrink()
this.pourCup()
this.addCondiment()
}
}
/* 咖啡 */
const coffee = new Beverage({
/* 冲泡咖啡,覆盖抽象方法 */
brewDrink: function() { console.log('冲泡咖啡') },
/* 加调味品,覆盖抽象方法 */
addCondiment: function() { console.log('加点奶和糖') }
})
coffee.init()
场景例子
- 一次性实现一个算法的不变的部分,并将可变的行为留给子类来实现
- 子类中公共的行为应被提取出来并集中到一个公共父类中的避免代码重复
优点
- 提取了公共代码部分,易于维护
缺点
- 增加了系统复杂度,主要是增加了的抽象类和类间联系
职责链模式
使多个对象都有机会处理请求,从而避免请求的发送者和接受者之间的耦合关系,将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止
// 请假审批,需要组长审批、经理审批、总监审批
class Action {
constructor(name) {
this.name = name
this.nextAction = null
}
setNextAction(action) {
this.nextAction = action
}
handle() {
console.log( `${this.name} 审批`)
if (this.nextAction != null) {
this.nextAction.handle()
}
}
}
let a1 = new Action("组长")
let a2 = new Action("经理")
let a3 = new Action("总监")
a1.setNextAction(a2)
a2.setNextAction(a3)
a1.handle()
场景例子
- JS 中的事件冒泡
- 作用域链
- 原型链
优点
- 降低耦合度。它将请求的发送者和接收者解耦。
- 简化了对象。使得对象不需要知道链的结构
- 增强给对象指派职责的灵活性。通过改变链内的成员或者调动它们的次序,允许动态地新增或者删除责任
- 增加新的请求处理类很方便。
缺点
- 不能保证某个请求一定会被链中的节点处理,这种情况可以在链尾增加一个保底的接受者节点来处理这种即将离开链尾的请求。
- 使程序中多了很多节点对象,可能再一次请求的过程中,大部分的节点并没有起到实质性的作用。他们的作用仅仅是让请求传递下去,从性能当面考虑,要避免过长的职责链到来的性能损耗。
命令模式
将一个请求封装成一个对象,从而让你使用不同的请求把客户端参数化,对请求排队或者记录请求日志,可以提供命令的撤销和恢复功能。
// 接收者类
class Receiver {
execute() {
console.log('接收者执行请求')
}
}
// 命令者
class Command {
constructor(receiver) {
this.receiver = receiver
}
execute () {
console.log('命令');
this.receiver.execute()
}
}
// 触发者
class Invoker {
constructor(command) {
this.command = command
}
invoke() {
console.log('开始')
this.command.execute()
}
}
// 仓库
const warehouse = new Receiver();
// 订单
const order = new Command(warehouse);
// 客户
const client = new Invoker(order);
client.invoke()
优点
- 对命令进行封装,使命令易于扩展和修改
- 命令发出者和接受者解耦,使发出者不需要知道命令的具体执行过程即可执行
缺点
- 使用命令模式可能会导致某些系统有过多的具体命令类。
备忘录模式
在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可将该对象恢复到保存的状态。
//备忘类
class Memento{
constructor(content){
this.content = content
}
getContent(){
return this.content
}
}
// 备忘列表
class CareTaker {
constructor(){
this.list = []
}
add(memento){
this.list.push(memento)
}
get(index){
return this.list[index]
}
}
// 编辑器
class Editor {
constructor(){
this.content = null
}
setContent(content){
this.content = content
}
getContent(){
return this.content
}
saveContentToMemento(){
return new Memento(this.content)
}
getContentFromMemento(memento){
this.content = memento.getContent()
}
}
//测试代码
let editor = new Editor()
let careTaker = new CareTaker()
editor.setContent('111')
editor.setContent('222')
careTaker.add(editor.saveContentToMemento())
editor.setContent('333')
careTaker.add(editor.saveContentToMemento())
editor.setContent('444')
console.log(editor.getContent()) //444
editor.getContentFromMemento(careTaker.get(1))
console.log(editor.getContent()) //333
editor.getContentFromMemento(careTaker.get(0))
console.log(editor.getContent()) //222
场景例子
- 分页控件
- 撤销组件
优点
- 给用户提供了一种可以恢复状态的机制,可以使用户能够比较方便地回到某个历史的状态
缺点
- 消耗资源。如果类的成员变量过多,势必会占用比较大的资源,而且每一次保存都会消耗一定的内存。
中介者模式
解除对象与对象之间的紧耦合关系。增加一个中介者对象后,所有的 相关对象都通过中介者对象来通信,而不是互相引用,所以当一个对象发生改变时,只需要通知 中介者对象即可。中介者使各对象之间耦合松散,而且可以独立地改变它们之间的交互。中介者 模式使网状的多对多关系变成了相对简单的一对多关系(类似于观察者模式,但是单向的,由中介者统一管理。)
class A {
constructor() {
this.number = 0
}
setNumber(num, m) {
this.number = num
if (m) {
m.setB()
}
}
}
class B {
constructor() {
this.number = 0
}
setNumber(num, m) {
this.number = num
if (m) {
m.setA()
}
}
}
class Mediator {
constructor(a, b) {
this.a = a
this.b = b
}
setA() {
let number = this.b.number
this.a.setNumber(number * 10)
}
setB() {
let number = this.a.number
this.b.setNumber(number / 10)
}
}
let a = new A()
let b = new B()
let m = new Mediator(a, b)
a.setNumber(10, m)
console.log(a.number, b.number)
b.setNumber(10, m)
console.log(a.number, b.number)
场景例子
- 系统中对象之间存在比较复杂的引用关系,导致它们之间的依赖关系结构混乱而且难以复用该对象
- 想通过一个中间类来封装多个类中的行为,而又不想生成太多的子类。
优点
使各对象之间耦合松散,而且可以独立地改变它们之间的交互 中介者和对象一对多的关系取代了对象之间的网状多对多的关系 如果对象之间的复杂耦合度导致维护很困难,而且耦合度随项目变化增速很快,就需要中介者重构代码
缺点
- 系统中会新增一个中介者对象,因 为对象之间交互的复杂性,转移成了中介者对象的复杂性,使得中介者对象经常是巨大的。中介 者对象自身往往就是一个难以维护的对象。
解释器模式
给定一个语言, 定义它的文法的一种表示,并定义一个解释器, 该解释器使用该表示来解释语言中的句子。 此例来自心谭博客
class Context {
constructor() {
this._list = []; // 存放 终结符表达式
this._sum = 0; // 存放 非终结符表达式(运算结果)
}
get sum() {
return this._sum;
}
set sum(newValue) {
this._sum = newValue;
}
add(expression) {
this._list.push(expression);
}
get list() {
return [...this._list];
}
}
class PlusExpression {
interpret(context) {
if (!(context instanceof Context)) {
throw new Error("TypeError");
}
context.sum = ++context.sum;
}
}
class MinusExpression {
interpret(context) {
if (!(context instanceof Context)) {
throw new Error("TypeError");
}
context.sum = --context.sum;
}
}
/** 以下是测试代码 **/
const context = new Context();
// 依次添加: 加法 | 加法 | 减法 表达式
context.add(new PlusExpression());
context.add(new PlusExpression());
context.add(new MinusExpression());
// 依次执行: 加法 | 加法 | 减法 表达式
context.list.forEach(expression => expression.interpret(context));
console.log(context.sum);
优点
- 易于改变和扩展文法。
- 由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法
缺点
- 执行效率较低,在解释器模式中使用了大量的循环和递归调用,因此在解释较为复杂的句子时其速度慢
- 对于复杂的文法比较难维护
访问者模式
表示一个作用于某对象结构中的各元素的操作。它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
// 访问者
class Visitor {
constructor() {}
visitConcreteElement(ConcreteElement) {
ConcreteElement.operation()
}
}
// 元素类
class ConcreteElement{
constructor() {
}
operation() {
console.log("ConcreteElement.operation invoked");
}
accept(visitor) {
visitor.visitConcreteElement(this)
}
}
// client
let visitor = new Visitor()
let element = new ConcreteElement()
element.accept(visitor)
场景例子
- 对象结构中对象对应的类很少改变,但经常需要在此对象结构上定义新的操作
- 需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免让这些操作“污染“这些对象的类,也不希望在增加新操作时修改这些类。
优点
- 符合单一职责原则
- 优秀的扩展性
- 灵活性
缺点
- 具体元素对访问者公布细节,违反了迪米特原则
- 违反了依赖倒置原则,依赖了具体类,没有依赖抽象。
- 具体元素变更比较困难
链接:https://juejin.cn/post/6844904032826294286
一、什么是控制反转
IoC(Inversion of Control)控制反转,是面向对象编程中的一种设计原则,用来降低计算机代码之间的耦合度。
完整版:在传统面向对象的编码过程中,当类与类之间存在依赖关系时,通常会直接在类的内部创建依赖对象,这样就导致类与类之间形成了耦合,依赖关系越复杂,耦合程度就会越高,而耦合度高的代码会非常难以进行修改和单元测试。而 IoC 则是专门提供一个容器,进行依赖对象的创建和查找,将对依赖对象的控制权由类内部交到容器这里,这样就实现了类与类的解耦,保证所有的类都是可以灵活修改。
二、什么是 DI
IoC 只是一种设计原则,而 DI 则是实现 IoC 的一种实现技术;
理解 DI 的关键是 “谁依赖了谁,为什么需要依赖,谁注入了谁,注入了什么”:
- 谁依赖了谁:当然是应用程序依赖
IoC 容器; - 为什么需要依赖:应用程序需要
IoC 容器来提供对象需要的外部资源(包括对象、资源、常量数据); - 谁注入谁:很明显是
IoC 容器注入应用程序依赖的对象; - 注入了什么:注入某个对象所需的外部资源(包括对象、资源、常量数据)。
参考文章
响应式页面开发
响应式页面开发的能力可以定义为:
利用一套代码实现页面的布局和排版以适配不同分辨率的设备。
响应式页面开发要求我们解决两大问题:
- 为不同特性(如横屏还是竖屏等)的浏览器视窗使用不同的样式代码
- 让页面元素的尺寸能够依据浏览器视窗尺寸变化而平滑变化
本小节的学习目标是学会解决上述问题并能够开发这样一个经典的移动端响应式页面:
我们分 3 个步骤来实现这样一个响应式页面。
步骤 1 - 添加 viewport meta 标签
在页头 head 标签内添加 viewport meta 标签是实现响应式页面的第一步。
viewport meta 标签源于 Apple 公司,用来定义 iOS Safari 浏览器展示网页内容的可视范围及缩放比率。它虽然没有成为W3C标准,但是被其他绝大多数的移动端浏览器所支持(目前已知 IE Mobile 10 不支持)。W3C 尝试将 viewport meta 标签的功能进行标准化并通过 CSS 的 @viewport 规则来实现同样的功能,但这个标准目前还在草案中,兼容性也没有 viewport meta 标签好。
PageSpeed 准则
Google 网页性能分析工具 PageSpeed Insights 的其中一条准则就是:
网页应在 head 标签内添加 viewport meta 标签,以便优化在移动设备上的展示效果,其推荐的设置为:
<meta name="viewport" content="width=device-width, initial-scale=1">
扩展阅读
- Mozilla《Using the viewport meta tag to control layout on mobile browsers》
- Google《Configure the viewport》
- Mozilla《@viewport》
步骤 2 - 使用 Media Queries
Media Queries 是为指定特性的浏览器视窗应用指定样式的手段,可以看成是 CSS 样式的过滤器或拦截器,通常情况下它可以通过 「@media 规则」结合「6 个查询参数」来拦截设备的浏览器特性(如显示类型、视窗高度、视窗宽度、横竖屏等),藉此可以为不同的特性应用不同的样式代码(相当于为不同的设备应用了不同的 CSS 样式)。
6 个参数
| 参数名称 | 参数描述 |
|---|---|
| min-width | 当视窗宽度大于或等于指定值时,@media 规则下的样式将被应用 |
| min-width | 当视窗宽度大于或等于指定值时,@media 规则下的样式将被应用 |
| max-width | 当视窗宽度小于或等于指定值时,@media 规则下的样式将被应用 |
| min-height | 当视窗高度大于或等于指定值时,@media 规则下的样式将被应用 |
| max-height | 当视窗高度小于或等于指定值时,@media 规则下的样式将被应用 |
| orientation=portrait | 当视窗高度大于或等于宽度时,@media 规则下的样式将被应用 |
| orientation=landscape | 当视窗宽度大于高度时,@media 规则下的样式将被应用 |
2 种用法
方法 1,使用 link 标签,根据指定特性引入特定的外部样式文件
<link rel="stylesheet" media="(max-width: 640px)" href="max-640px.css">
方法 2,直接在 style 标签或 样式文件内使用 @media 规则
@media (max-width: 640px) {
/*当视窗宽度小于或等于 640px 时,这里的样式将生效*/
}
样式断点
Media Queries 所使用的查询参数的临界值又可称为「样式断点」。 在响应式页面开发过程中,对于「样式断点」我们需要掌握 2 个重要的技巧:
依据目标设备的分辨率,制定一套合适的样式断点,并为不同的断点定制必要的 CSS 样式。 移动端优先的页面,可使用 min-width 查询参数从小到大来定义断点。 如果我们页面的响应式设计要涵盖从手机到高清大屏幕,什么样的「样式断点」比较合理呢?
我们可以从业界一些热门可靠的 CSS 框架中寻找参考答案,例如 Bulma,其采用的「样式断点」有 5 个:
| 断点名称 | 断点描述) |
|---|---|
| mobile | 移动设备断点,视窗宽度 ≤ 768 px |
| tablet | 平板电脑设备断点,视窗宽度 ≥ 769 px |
| desktop | 桌面电脑断点,视窗宽度 ≥ 1024 px |
| widescreen | 宽屏电脑断点,视窗宽度 ≥ 1216 px |
| fullhd | 高清宽屏电脑断点,视窗宽度 ≥ 1408 px |
在实际工作中,「样式断点」的制定需要我们同视觉设计师一起沟通确认,因为视觉设计师可能需要根据不同的断点为页面设计不同的视觉表现。
一个小例子
如果针对 tablet 及以上的设备定制样式,我们就可以这样写了:
@media (min-width: 769px) {
/* tablet 及以上的设备,页面背景色设置为红色 */
body {
background-color: red;
}
}
课外作业
- 使用桌面版的 Chrome 浏览器,打开 Google 的 在线 Media Queries 例子 直观感受下使用 Media Queries 的效果(请注意缩放浏览器窗口观察页面展示效果)
- 了解 Bulma 框架
扩展阅读
步骤 3 - 使用 Viewport 单位及 rem
Media Queries 只解决了「为不同特性的浏览器视窗使用不同的样式代码」的问题,而 Viewport 单位及 rem 的应用,则是为了解决第二个问题:让页面元素的尺寸能够依据浏览器视窗尺寸变化而平滑变化。
关于 Viewport 单位及 rem 单位的基本概念,可通过下面的扩展阅读进行回顾复习。
BTW:本文所提及的 Viewport,译为「视窗」,其含义与扩展阅读中相关文章中的「视口」一致。
方法 1 - 仅使用 vw 作为 CSS 长度单位
在仅使用 vw 单位作为唯一 CSS 单位时,我们需遵守:
- 利用 Sass 函数将设计稿元素尺寸的像素单位转换为 vw 单位
// iPhone 6尺寸作为设计稿基准
$vw_base: 375;
@function vw($px) {
@return ($px / $vm_base) * 100vw;
}
- 无论是文本字号大小还是布局高宽、间距、留白等都使用 vw 作为 CSS 单位
.mod_nav {
background-color: #fff;
&_list {
display: flex;
padding: vw(15) vw(10) vw(10); // 内间距
&_item {
flex: 1;
text-align: center;
font-size: vw(10); // 字体大小
&_logo {
display: block;
margin: 0 auto;
width: vw(40); // 宽度
height: vw(40); // 高度
img {
display: block;
margin: 0 auto;
max-width: 100%;
}
}
&_name {
margin-top: vw(2);
}
}
}
}
- 1 物理像素线(也就是普通屏幕下 1px ,高清屏幕下 0.5px 的情况)采用 transform 属性 scale 实现
.mod_grid {
position: relative;
&::after {
// 实现1物理像素的下边框线
content: '';
position: absolute;
z-index: 1;
pointer-events: none;
background-color: #ddd;
height: 1px;
left: 0;
right: 0;
top: 0;
@media only screen and (-webkit-min-device-pixel-ratio: 2) {
-webkit-transform: scaleY(0.5);
-webkit-transform-origin: 50% 0%;
}
}
...
}
- 对于需要保持高宽比的图,应改用 padding-top 实现
.mod_banner {
position: relative;
// 使用padding-top 实现宽高比为 100:750 的图片区域
padding-top: percentage(100/750);
height: 0;
overflow: hidden;
img {
width: 100%;
height: auto;
position: absolute;
left: 0;
top: 0;
}
}
由此,我们不需要增加其他任何额外的脚本代码就能够轻易实现一个常见布局的响应式页面,效果如下:
体验地址:视口单位布局 —— vw 单位
友情提醒:桌面版 Chrome 支持的字体大小默认不能小于 12PX,可通过 「chrome://settings/ 显示高级设置-网络内容-自定义字体-最小字号(滑到最小)」设置后再到模拟器里体验 DEMO。
方法 2 - vw 搭配 rem,寻找最优解
方法 1 实现的响应式页面虽然看起来适配得很好,但是你会发现由于它是利用 Viewport 单位实现的布局,依赖于视窗大小而自动缩放,无论视窗过大还是过小,它也随着视窗过大或者过小,失去了最大最小宽度的限制,有时候不一定是我们所期待的展示效果。试想一下一个 750px 宽的设计稿在 1920px 的大屏显示器上的糟糕样子。
当然,你可以不在乎移动端页面在 PC 上的展现效果,但如果有低成本却有效的办法来修复这样的小瑕疵,是真切可以为部分用户提升体验的。
我们可以结合 rem 单位来实现页面的布局。rem 弹性布局的核心在于根据视窗大小变化动态改变根元素的字体大小,那么我们可以通过以下步骤来进行优化:
- 给根元素的字体大小设置随着视窗变化而变化的 vw 单位,这样就可以实现动态改变其大小
- 其他元素的文本字号大小、布局高宽、间距、留白都使用 rem 单位
- 限制根元素字体大小的最大最小值,配合 body 加上最大宽度和最小宽度,实现布局宽度的最大最小限制
核心代码实现如下:
// rem 单位换算:定为 75px 只是方便运算,750px-75px、640-64px、1080px-108px,如此类推
$vw_fontsize: 75; // iPhone 6尺寸的根元素大小基准值
@function rem($px) {
@return ($px / $vw_fontsize ) * 1rem;
}
// 根元素大小使用 vw 单位
$vw_design: 750;
html {
font-size: ($vw_fontsize / ($vw_design / 2)) * 100vw;
// 同时,通过Media Queries 限制根元素最大最小值
@media screen and (max-width: 320px) {
font-size: 64px;
}
@media screen and (min-width: 540px) {
font-size: 108px;
}
}
// body 也增加最大最小宽度限制,避免默认100%宽度的 block 元素跟随 body 而过大过小
body {
max-width: 540px;
min-width: 320px;
}
体验地址:https://jdc.jd.com/demo/ting/vw_rem_layout.html
扩展阅读
- Mozilla《Length》
- 凹凸实验室 《利用视口单位实现适配布局》
小结
在实际工作过程中,考虑到设计以及开发成本,视觉设计师是不大可能为每种不同分辨率的设备分别设计不同的稿子的,拿移动端页面来说,通常会以 iPhone 7 的分辨率(宽为 750 px)作为基准分辨率来出设计稿。因此「响应式页面开发」也便成为了移动互联网时代「H5 开发」的必备技能。
本小节所介绍的「利用 Viewport 单位及 rem 实现响应式页面」,相对于传统的 JavaScript 脚本结合 rem 的方式来得更简单优雅。
一、屏幕适配方案和优劣
| 方案 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| vw vh | 1.按照设计稿的尺寸,将px按比例计算转为vw和vh | 1.可以动态计算图表的宽高,字体等,灵活性较高 2.当屏幕比例跟 ui 稿不一致时,不会出现两边留白情况 | 1.每个图表都需要单独做字体、间距、位移的适配,比较麻烦 |
| scale | 1.通过 scale 属性,根据屏幕大小,对图表进行整体的等比缩放 | 1.代码量少,适配简单 2.一次处理后不需要在各个图表中再去单独适配 | 1.因为是根据 ui 稿等比缩放,当大屏跟 ui 稿的比例不一样时,会出现周边留白情况 2.当缩放比例过大时候,字体会有一点点模糊,就一点点 3.当缩放比例过大时候,事件热区会偏移。 |
| rem + vw vh | 1.获得 rem 的基准值 2.动态的计算html根元素的font-size 3.图表中通过 vw vh 动态计算字体、间距、位移等 | 1.布局的自适应代码量少,适配简单 | 1.因为是根据 ui 稿等比缩放,当大屏跟 ui 稿的比例不一样时,会出现周边留白情况 2.图表需要单个做字体、间距、位移的适配 |
1. 移动端1px线适配
使用 vw 适配屏幕大小方案,其中有一个缺点就是在 Retina 屏下,无法很好的展示真正的 1px 物理像素线条。
设计师想要的 retina 下 border: 1px,其实是 1 物理像素宽,而不是 1 CSS 像素宽度,对于 CSS 而言:
- 在 dpr = 1 时,此时 1 物理像素等于 1 CSS 像素宽度;
- 在 dpr = 2 时,此时 1 物理像素等于 0.5 CSS 宽度像素,可以认为
border-width: 1px这里的 1px 其实是 1 CSS像素宽度,等于 2 像素物理宽度,设计师其实想要的是border-width: 0.5px; - 在 dpr = 3 时,此时 1 物理像素等于 0.33 CSS 宽度像素,设计师其实想要的是
border: 0.333px
然而,并不是所有手机浏览器都能识别 border-width: 0.5px,在 iOS7 以下,Android 等其他系统里,小于 1px 的单位会被当成为 0px 处理,那么如何实现这 0.5px、0.33px 呢?
这里介绍几种方法:
- 渐变实现: 使用两种颜色填充 1px 宽内容
- 使用css transform 缩放实现:对 1px 高度线条进行0.5/0.33倍缩放
- 使用图片实现(base64):background-image 为一个base64 编码格式图片
- 使用SVG实现(嵌入 background url):background-image 为一个svg 编码格式图片
2. rem 适配方式
当初为了能让页面更好的适配各种不同的终端,通过Hack手段来根据设备的dpr值相应改变标签中viewport的值:
<!-- dpr = 1-->
<meta name="viewport" content="initial-scale=scale,maximum-scale=scale,minimum-scale=scale,user-scalable=no">
<!-- dpr = 2-->
<meta name="viewport" content="initial-scale=0.5,maximum-scale=0.5,minimum-scale=0.5,user-scalable=no">
<!-- dpr = 3-->
<meta name="viewport" content="initial-scale=0.3333333333,maximum-scale=0.3333333333,minimum-scale=0.3333333333,user-scalable=no">
从而让页面达么缩放的效果,也变相的实现页面的适配功能。而其主要的思想有三点:
- 根据dpr的值来修改 viewport 实现1px的线
- 根据dpr的值来修改 html 的 font-size,从而使用rem实现等比缩放
- 使用Hack手段用rem模拟vw特性
rem 缺陷:
- 在宽度较大的设备上,整体缩放的太大了。而用户的预期应该是看到更多内容。你可以阅读这篇文章《为什么2022年不建议你在小程序中用rpx》了解整体缩放的体验问题。
- 它的兼容性并不好,依然存在一些问题,尤其是尺寸遇到小数点时,bug较多。
- 开发天然喜欢px单位,像rem,em,vw,vh这些单位,一般都不是UI设计稿标注的尺寸,开发时需要转换成本。不如直接在代码中写px直观高效
- 兼容性更好的替代方案 viewport (vw),几乎所有手机浏览器都支持viewport
二、vw、vh 适配方案
严格来说,使用 rem 进行页面适配其实是一种 hack 手段,rem 单位的初衷本身并不是用来进行移动端页面宽度适配的。
百分比适配方案的核心需要一个全局通用的基准单位,rem 是不错,但是需要借助 Javascript 进行动态修改根元素的 font-size,而 vw/vh(vmax/vmin) 的出现则很好弥补 rem 需要 JS 辅助的缺点。
根据相关的测试,可以使用 vw 进行长度单位的有:
- 容器大小适配,可以使用 vw
- 文本大小的适配,可以使用 vw
- 大于 1px 的边框、圆角、阴影都可以使用 vw
- 内距和外距,可以使用 vw
vw 优势:
- vw 也是一个相对单位(1vw = window.innerWidth * 1%),不需要 js 辅助;
- postcss-px-to-viewport 自动转换插件,代码中写px 单位,打包后即可转化为 vw 单位;
vw 劣势:
- 没能很好的解决 1px 边框在高清屏下的显示问题,需要自行处理
- 由于 vw 方案是完全的等比缩放,在完全等比还原设计稿的同时带来的一个问题是无法很好的限定一个最大最小宽度值,由于 rem 方案是借助 Javascript 的,所以这一点 rem 比 vw 会更加的灵活(试想一下一个 750px 宽的设计稿在 1920px 的大屏显示器上的糟糕样子)
三、vw和rem结合适配,布局更优化
由于 vw 是利用视口单位实现的布局,依赖于视口大小而自动缩放,无论视口过大还是过小,它也随着视口过大或者过小,失去了最大最小宽度的限制。
为了修复这个问题,可以结合rem单位来实现布局, rem 弹性布局的核心在于动态改变根元素大小,可以通过:
-
给根元素大小设置随着视口变化而变化的 vw 单位,这样就可以实现动态改变其大小。
-
限制根元素字体大小的最大最小值,配合 body 加上最大宽度和最小宽度
这样我们就能够实现对布局宽度的最大最小限制。因此,根据以上条件,我们可以得出代码实现如下:
// rem 单位换算:定为 75px 只是方便运算,750px-75px、640-64px、1080px-108px,如此类推
$vw_fontsize: 75; // iPhone 6尺寸的根元素大小基准值
@function rem($px) {
@return ($px / $vw_fontsize ) * 1rem;
}
// 根元素大小使用 vw 单位
$vw_design: 750;
html {
font-size: ($vw_fontsize / ($vw_design / 2)) * 100vw;
// 同时,通过Media Queries 限制根元素最大最小值
@media screen and (max-width: 320px) {
font-size: 64px;
}
@media screen and (min-width: 540px) {
font-size: 108px;
}
}
// body 也增加最大最小宽度限制,避免默认100%宽度的 block 元素跟随 body 而过大过小
body {
max-width: 540px;
min-width: 320px;
}
优势:
- 相对来说用户视觉体验更好,增加了最大最小宽度的限制;
- 更重要是,如果选择主流的rem弹性布局方式作为项目开发的适配页面方法,这种做法更适合于后期项目从 rem 单位过渡到 vw 单位。只需要通过改变根元素大小的计算方式,你就可以不需要其他任何的处理,就无缝过渡到另一种CSS单位,更何况vw单位的使用必然会成为一种更好适配方式,目前它只是碍于兼容性的支持而得不到广泛的应用。
四、左侧宽度固定,右侧宽度自适应的布局
DOM结构
<div class="box">
<div class="box-left"></div>
<div class="box-right"></div>
</div>
- 利用 float + margin 实现
.box {
height: 200px;
}
.box > div {
height: 100%;
}
.box-left {
width: 200px;
float: left;
background-color: blue;
}
.box-right {
margin-left: 200px;
background-color: red;
}
- 利用 calc 计算宽度
.box {
height: 200px;
}
.box > div {
height: 100%;
}
.box-left {
width: 200px;
float: left;
background-color: blue;
}
.box-right {
width: calc(100% - 200px);
float: right;
background-color: red;
}
- 利用 float + overflow 实现
.box {
height: 200px;
}
.box > div {
height: 100%;
}
.box-left {
width: 200px;
float: left;
background-color: blue;
}
.box-right {
overflow: hidden;
background-color: red;
}
- 利用flex实现(flex-basic)
.box {
height: 200px;
display: flex;
}
.box > div {
height: 100%;
}
.box-left {
width: 200px;
background-color: blue;
}
.box-right {
flex: 1; // 设置flex-grow属性为1,默认为0
overflow: hidden;
background-color: red;
}
flex 布局:语法篇
阮一峰的网络日志: Flex 布局教程:语法篇
五、css 选择器
阮一峰:CSS选择器笔记
六、css样式权重和优先级
权重记忆口诀:从0开始,一个行内样式+1000,一个id选择器+100,一个属性选择器、class或者伪类+10,一个元素选择器,或者伪元素+1,通配符+0。
- 样式重复多写情况:后面的会覆盖前面的;
- 不同的权重,权重值高则生效;
- !important (提升样式优先级),两种样式都使用 !important 时,权重值大的优先级更高;
- 行内、内联和外联样式优先级,根据权重值来计算,行内样式的权重值最大;
- 内联和外联样式优先级:内联样式和外联样式的优先级和加载顺序有关;
- 权重相等的情况下:同等权重下,靠近目标的优先;
第一问:什么是盒模型?
可以说,页面就是由一个个盒模型堆砌起来的,每个HTML元素都可以叫做盒模型,盒模型由外而内包括:外边距(margin)、边框(border)、填充(亦称内边距)(padding)、内容(content)。它在页面中所占的实际宽度是margin + border + padding + content 的宽度相加。 但是,盒模型有标准盒模型和IE的盒模型。
第二问:两者的区别是什么?
标准的(W3C)盒模型:
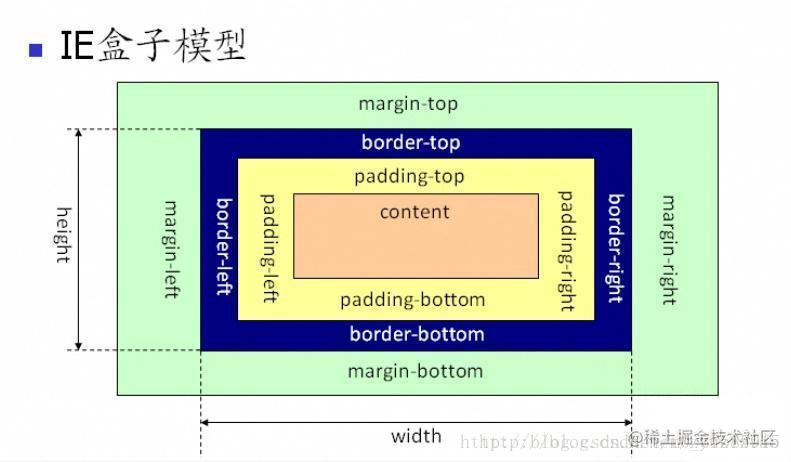
第三问:怎么设置这两种模型呢?
很简单,通过设置 box-sizing:content-box(W3C)/border-box(IE) 就可以达到自由切换的效果。
第四问JS怎么获取和设置盒模型的宽高呢,你能想到几种方法?
- 第一种:
dom.style.width/height这种方法只能获取使用内联样式的元素的宽和高。 - 第二种:
dom.currentStyle.width/height这种方法获取的是浏览器渲染以后的元素的宽和高,无论是用何种方式引入的css样式都可以,但只有IE浏览器支持这种写法。 - 第三种:
window.getComputedStyle(dom).width/height这种方法获取的也是浏览器渲染以后的元素的宽和高,但这种写法兼容性更好一些。 - 第四种:
dom.getBoundingClientRect().width/height这种方法经常使用的场所是,计算一个元素的绝对位置(相对于视窗左上角),它能拿到元素的left、top、width、height 4个属性。
第五问:描述一下下面盒子的大小,颜色什么的(content-box模型)
<html>
<style>
body{
background-color: gray;
}
div{
color: blue;
width: 100px;
background-color: pink;
border: 10px solid;
padding: 20px;
}
</style>
<body>
<div></div>
</body>
</html>
这里不指考了一点,问题列一下:
- 整个盒子的大小
- padding的颜色
- border的颜色
- height为0了,看得见盒子吗?
答案:如图所示
- 整个盒子的大小 = 0 (因为height为0)
- padding的颜色 = pink(继承content的颜色)
- border的颜色 = blue(继承color字体的颜色,默认为black)
- height为0了,看得见盒子吗? (虽然height为0,但是看得见盒子,因为有border和padding)
这里需要注意:
- 如果没有写border-style,那么边框的宽度不管设置成多少,都是无效的。
- border-color的颜色默认跟字体颜色相同
- padding颜色跟背景颜色相同
第六问:当small盒子设置成圆形时,内容会超出圆形吗?为什么
<html>
<style>
body{
background-color: gray;
}
.big{
width: 400px;
height: 400px;
background-color: pink;
}
.small{
width: 100px;
height: 100px;
background-color: red;
border-radius: 50%;
overflow-wrap: break-word;
}
</style>
<body>
<div class="big">
<div class="small">
ddddddddddddddddddddddddddddddddddddddddddd
</div>
</div>
</body>
</html>
会超出圆形。原因如图所示,是因为border-radius只是改变视觉上的效果,实际上盒子占据的空间还是不变的。
第七问:当元素设置成inline-block会出现什么问题?怎么消除?
这是网易有道的小姐姐面试官的问题,我承认我确实不知道这个问题! 真正意义上的inline-block水平呈现的元素间,换行显示或空格分隔的情况下会有间距,很简单的个例子: 我们使用CSS更改非inline-block水平元素为inline-block水平,也会有该问题
.space a {
display: inline-block;
padding: .5em 1em;
background-color: #cad5eb;
}
<div class="space">
<a href="##">惆怅</a>
<a href="##">淡定</a>
<a href="##">热血</a>
</div>
去除inline-block元素间间距的N种方法:
- 元素间留白间距出现的原因就是标签段之间的空格,因此,去掉HTML中的空格,自然间距就木有了。考虑到代码可读性,显然连成一行的写法是不可取的,我们可以:
<div class="space">
<a href="##">
惆怅</a><a href="##">
淡定</a><a href="##">
热血</a>
</div>
或者是:
<div class="space">
<a href="##">惆怅</a
><a href="##">淡定</a
><a href="##">热血</a>
</div>
或者是借助HTML注释:
<div class="space">
<a href="##">惆怅</a><!--
--><a href="##">淡定</a><!--
--><a href="##">热血</a>
</div>
- 使用margin负值
- 让闭合标签吃胶囊
- 使用font-size:0 详细的可以看看这篇文章 去除inline-block元素间间距的N种方法
第八问:行内元素可以设置padding,margin吗?
- 第一:行内元素与宽度 宽度不起作用
span {
width:200px;
}
没有变化 第二:行内元素与高度 高度不起作用
span{
height:200px;
}
没用变化
第三:行内元素与padding,margin
span{
padding:200px;
}
影响左右,不影响上下 ,span包裹的文字左右位置改变,上下位置不变,但背景色会覆盖上面元素的内容。 如图所示:
 行内元素(inline-block)的padding左右有效 ,但是由于设置padding上下不占页面空间,无法显示效果,所以无效。
行内元素(inline-block)的padding左右有效 ,但是由于设置padding上下不占页面空间,无法显示效果,所以无效。
第九问:padding:1px2px3px;则等效于什么?
简单来说就是 这四个值,分别代表上、右、下、左。如果没有写下的话,那就下复制上的,同理左复制右的值。 因此, 你应该明白了
- 当padding的值只有一个时,就是后面三个都复制了第一个
- 当写两个时,就是写了top和right,因此bottom复制top,left复制right
- 当写了三个时,就是写了top,right,bottom,因此left复制right。
这么简单的规则,再也不会忘记了吧。
第十问:内边距的百分数值是这么计算的
我们知道,padding可以这么设置:padding:100px,也可以 padding:20%,那当是百分比时是怎么计算的呢?就是根据父元素的宽度计算的;
第十一问:那为什么不根据自己的宽度呢?而要根据父元素
这个问题可以这么思考,如果不根据父元素,而是根据本身的宽度的话。那么当padding生效后,本身的宽度不就变大了吗?那么padding不是也要变大吗?这就陷入了死循环(哇塞!)。 或者要是本身没有宽度,那岂不是怎么设置padding都是无效的!!!
第十二问:什么是边距重叠?什么情况下会发生边距重叠?如何解决边距重叠?
边距重叠:两个box如果都设置了边距,那么在垂直方向上,两个box的边距会发生重叠,以绝对值大的那个为最终结果显示在页面上。 边距重叠分为两种:
- 同级关系的重叠:
同级元素在垂直方向上外边距会出现重叠情况,最后外边距的大小取两者绝对值大的那个**
<section class="fat">
<style type="text/css">
.fat {
background-color: #ccc;
}
.fat .child-one {
width: 100px;
height: 100px;
margin-bottom: 30px;
background-color: #f00;
}
.fat .child-two {
width: 100px;
height: 100px;
margin-top: 10px;
background-color: #345890;
}
</style>
<div class="child-one"></div>
<div class="child-two"></div>
</section>
- 父子关系的边距重叠:
父子关系,如果子元素设置了外边距,在没有把父元素变成BFC的情况下,父元素也会产生外边距。
给父元素添加 overflow:hidden 这样父元素就变为 BFC,不会随子元素产生外边距,但是父元素的高会变化
<section class="box" id="fat">
<style type="text/css">
#fat {
background-color: #f00;
overflow: hidden;
}
#fat .child {
margin-top: 10px;
height: 100px;
background-color: blue;
}
</style>
<article class="child"></article>
</section>
第十三问:第二种哪里算是外边距重叠???
实际上,这也是第一种的变形。
header {
background: goldenrod;
}
h1 {
margin: 1em;
}
<header>
<h1>Welcome to ConHugeCo</h1>
</header>
!(css)[./CSS盒模型/css面试4.png]
可以看到其实是header的margin为0,然后h1的margin为1em,因此header和h1的margin发生了重叠,然后header的margin就取1em和0两个值中最大的值了,所以当然取1em啦。
(网上有说是因为margin的传递性,但我并不同意,因为我实践了一下,发现不管父盒子有没有margin-top,父盒子只会选择两者值中的最大值,跟传递性似乎没啥关系)
第十四问:为什么回出现margin重叠的问题?粗俗点就是问设计者的脑子有问题吗?
这个就是问设计了margin重叠的巧妙用处。
这个曾经有位面试官问过我,我不知道,我请教了他,他说,在flex布局前,要实justify-content: space-evenly的效果,利用浮动布局,然后给每个盒子设置margin-right,margin-left就可以实现了,这样就不用去单独地再去设置第一个盒子的margin-left和最后一个盒子的margin-right,那时候我信了。
后来越想越不对,不是说margin水平方向不会发生重叠问题吗????
但是根据面试官的思路来的话,在垂直方向似乎就讲的通了。
<html>
<style>
body{
background-color: gray;
}
ul{
width: 300px;
height: 170px;
background-color: blue;
border: 1px solid;
}
li{
margin-top: 20px;
margin-bottom: 20px;
width: 40px;
height: 30px;
background-color: orange;
}
</style>
<body>
<ul>
<li></li>
<li></li>
<li></li>
</ul>
</body>
</html>

或许你有更好的说法,欢迎下方留言评论补充!!! 那该怎么解决margin边距重叠的问题呢? 解决方法就是生成BFC
第十五问:什么是BFC?
BFC 全称为块级格式化上下文 (Block Formatting Context) 。BFC是 W3C CSS 2.1 规范中的一个概念,它决定了元素如何对其内容进行定位以及与其他元素的关系和相互作用,当涉及到可视化布局的时候,Block Formatting Context提供了一个环境,HTML元素在这个环境中按照一定规则进行布局。一个环境中的元素不会影响到其它环境中的布局。比如浮动元素会形成BFC,浮动元素内部子元素的主要受该浮动元素影响,两个浮动元素之间是互不影响的。这里有点类似一个BFC就是一个独立的行政单位的意思。可以说BFC就是一个作用范围,把它理解成是一个独立的容器
第十六问:那么BFC的原理是什么呢?
- 内部的Box会在垂直方向上一个接一个的放置
- 垂直方向上的距离由margin决定。(完整的说法是:属于同一个BFC的两个相邻Box的margin会发生重叠(塌陷),与方向无关。)
- 每个元素的左外边距与包含块的左边界相接触(从左向右),即使浮动元素也是如此。(这说明BFC中子元素不会超出他的包含块,而position为absolute的元素可以超出他的包含块边界)
- BFC的区域不会与float的元素区域重叠
- 计算BFC的高度时,浮动子元素也参与计算
- BFC就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面元素,反之亦然
第十七问:BFC由什么条件创立?
- 浮动元素 (元素的 float 不是 none)
- 绝对定位元素 (元素具有 position 为 absolute 或 fixed)
- 内联块 (元素具有 display: inline-block)
- 表格单元格 (元素具有 display: table-cell,HTML表格单元格默认属性)
- 表格标题 (元素具有 display: table-caption, HTML表格标题默认属性)
- 弹性盒(flex或inline-flex)
- display: flow-root
- column-span: all
- 具有overflow 且值不是 visible 的块元素
总结:pdfo
BFC的约束规则
- 内部的盒会在垂直方向一个接一个排列(可以看作BFC中有一个的常规流)
- 处于同一个BFC中的元素相互影响,可能会发生外边距重叠
- 每个元素的margin box的左边,与容器块border box的左边相接触(对于从左往右的格式化,否则相反),即使存在浮动也是如此
- BFC就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素,反之亦然
- 计算BFC的高度时,考虑BFC所包含的所有元素,连浮动元素也参与计算
- 浮动盒区域不叠加到BFC上
第十八问: BFC的使用场景有哪些呢
- 可以用来自适应布局。
<!-- BFC不与float重叠 -->
<section id="layout">
<style media="screen">
#layout{
background: red;
}
#layout .left{
float: left;
width: 100px;
height: 100px;
background: #664664;
}
#layout .right{
height: 110px;
background: #ccc;
overflow: auto;
}
</style>
<div class="left"></div>
<div class="right"></div>
<!-- 利用BFC的这一个原理就可以实现两栏布局,左边定宽,右边自适应。不会相互影响,哪怕高度不相等。 -->
</section>
- 可以清除浮动:(塌陷问题)
<!-- BFC子元素即使是float也会参与计算 -->
<section id="float">
<style media="screen">
#float{
background: #434343;
overflow: auto;
}
#float .float{
float: left;
font-size: 30px;
}
</style>
<div class="float">我是浮动元素</div>
</section>
- 解决垂直边距重叠:
<section id="margin">
<style>
#margin{
background: pink;
overflow: hidden;
}
#margin>p{
margin: 5px auto 25px;
background: red;
}
#margin>div>p {
margin: 5px auto 20px;
background: red;
}
</style>
<p>1</p>
<div style="overflow:hidden">
<p>2</p>
</div>
<p>3</p>
<!-- 这样就会出现第一个p标签的margin-bottom不会和第二个p标签的margin-top重叠,这也是BFC元素的另一个原则,不会影响到外边的box,是一个独立的区域。 -->
</section>
第十九问:清除浮动的方法(最常用的4种)
这时候很多人会想到新建标签clear:both和float 方法,但是这两种方法并不推荐使用!
什么是clear:both
clear:both:本质就是闭合浮动, 就是让父盒子闭合出口和入口,不让子盒子出来
- 额外标签法(在最后一个浮动标签后,新加一个标签,给其设置
clear:both;)(不推荐)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<style>
.fahter{
width: 400px;
border: 1px solid deeppink;
}
.big{
width: 200px;
height: 200px;
background: darkorange;
float: left;
}
.small{
width: 120px;
height: 120px;
background: darkmagenta;
float: left;
}
.footer{
width: 900px;
height: 100px;
background: darkslateblue;
}
.clear{
clear:both;
}
</style>
</head>
<body>
<div class="fahter">
<div class="big">big</div>
<div class="small">small</div>
<div class="clear">额外标签法</div>
</div>
<div class="footer"></div>
</body>
</html>
 如果我们清除了浮动,父元素自动检测子盒子最高的高度,然后与其同高。
如果我们清除了浮动,父元素自动检测子盒子最高的高度,然后与其同高。
优点:通俗易懂,方便
缺点:添加无意义标签,语义化差 不建议使用。
- 父级添加overflow属性(父元素添加overflow:hidden)(不推荐)
通过触发BFC方式,实现清除浮动
.fahter{
width: 400px;
border: 1px solid deeppink;
overflow: hidden;
}
优点:代码简洁
缺点:内容增多的时候容易造成不会自动换行导致内容被隐藏掉,无法显示要溢出的元素
不推荐使用
- 使用after伪元素清除浮动(推荐使用)
.clearfix:after{/*伪元素是行内元素 正常浏览器清除浮动方法*/
content: "";
display: block;
height: 0;
clear:both;
visibility: hidden;
}
.clearfix{
*zoom: 1;/*ie6清除浮动的方式 *号只有IE6-IE7执行,其他浏览器不执行*/
}
<body>
<div class="fahter clearfix">
<div class="big">big</div>
<div class="small">small</div>
<!--<div class="clear">额外标签法</div>-->
</div>
<div class="footer"></div>
</body>
优点:符合闭合浮动思想,结构语义化正确
缺点:ie6-7不支持伪元素:after,使用zoom:1 触发 hasLayout.
推荐使用
- 使用before和after双伪元素清除浮动
.clearfix:after,.clearfix:before{
content: "";
display: table;
}
.clearfix:after{
clear: both;
}
.clearfix{
*zoom: 1;
}
<div class="fahter clearfix">
<div class="big">big</div>
<div class="small">small</div>
</div>
<div class="footer"></div>
优点:代码更简洁
缺点:用zoom:1触发hasLayout.
推荐使用
- 浮动父元素
img{
width:50px;
border:1px solid #8e8e8e;
float:left;
}
<div style="float:left">
<img src="images/search.jpg"/>
<img src="images/tel.jpg"/>
<img src="images/weixin.png"/>
<img src="images/nav_left.jpg"/>
</div>
这种方式也不推荐,了解即可。
参考链接:
- https://juejin.cn/post/6880111680153059341
TODO
参考链接: https://juejin.cn/post/6844903679242305544
移动端适配要点
- 媒体查询,边界断点的规则设定(Media queries && break point)
- 内容的可伸缩性效果(Flexibel visuals)
- 流式网格布局(Fluid grids)
- 主要内容呈现及图片的高质量(Main content and high quality)
移动端屏幕适配方案
通常而言,设计师只会给出单一分辨率下的设计稿,而我们要做的,就是以这个设计稿为基准,去适配所有不同大小的移动端设备。
1. 一些基础概念
- 设备独立像素 以 iPhone6/7/8为例,这里我们打开 Chrome 开发者工具:
 这里的
这里的 375 * 667 表示的是什么呢,表示的是设备独立像素(DIP),也可以理解为 CSS 像素,也称为逻辑像素:
设备独立像素 = CSS 像素 = 逻辑像素
- 物理像素
OK,那么,什么又是物理像素呢。我们到电商网站购买手机,都会看一看手机的参数,以 JD 上的 iPhone7 为例:

可以看到,iPhone7 的分辨率是 1334 x 750,这里描述的就是屏幕实际的物理像素。
物理像素,又称为设备像素。显示屏是由一个个物理像素点组成的,1334 x 750 表示手机分别在垂直和水平上所具有的像素点数。通过控制每个像素点的颜色,就可以使屏幕显示出不同的图像,屏幕从工厂出来那天起,它上面的物理像素点就固定不变了,单位为pt。
设备像素 = 物理像素
- DPR(Device Pixel Ratio) 设备像素比
OK,有了上面两个概念,就可以顺理成章引出下一个概念:DPR(Device Pixel Ratio) 设备像素比,这个与我们通常说的**视网膜屏(多倍屏,Retina屏)**有关。
设备像素比描述的是未缩放状态下,物理像素和设备独立像素的初始比例关系。
简单的计算公式:
DPR = 物理像素 / 设备独立像素
我们套用一下上面 iPhone7 的数据(取设备的物理像素宽度与设备独立像素宽度进行计算):
iPhone7’s DPR = iPhone7’s 物理像素宽度 / iPhone7’s 设备独立像素宽度 = 2
750 / 375 = 2 或者是 1334 / 667 = 2
可以得到 iPhone7 的 dpr 为 2。也就是我们常说的视网膜屏幕。
视网膜(Retina)屏幕是苹果公司“发明“的一个营销术语。 苹果公司将 dpr > 1 的屏幕称为视网膜屏幕。
在视网膜屏幕中,以 dpr = 2 为例,把 4(2x2) 个像素当 1 个像素使用,这样让屏幕看起来更精致,但是元素的大小本身却不会改变:
OK,到这里我们就完成了一个小的里程碑。我们通常说的H5手机适配也就是指的这两个维度:
- 适配不同屏幕大小,也就是适配不同屏幕下的 CSS 像素
- 适配不同像素密度,也就是适配不同屏幕下 dpr 不一致导致的一些问题
2. 适配不同屏幕大小
适配不同屏幕大小,也就是适配不同屏幕下的 CSS 像素。最早移动端屏幕 CSS 像素适配方案是CSS媒体查询。但是无法做到高保真接近 100% 的还原。 适配不同屏幕大小其实只需要遵循一条原则,确保页面元素大小的与屏幕大小保持一定比例。也就是:按比例还原设计稿
以页面宽度为基准的话,那么,
- 元素的宽度为:
209/375 = 55.73% - 元素的高度为:
80/375 = 21.33% - 元素的上左右边距依次计算…
这样,无论屏幕的 CSS 像素宽度是 320px 还是 375px 还是 414px,按照等量百分比还原出来的界面总是正确的。
然而,理想很丰满,现实很骨感。实现上述百分比方案的核心需要一个全局通用的基准单位,让所有百分比展示以它为基准,但是在 CSS 中,根据CSS Values and Units Module Level 4的定义:
百分比值总要相对于另一个量,比如长度。每个允许使用百分比值的属性,同时也要定义百分比值参照的那个量。这个量可以是相同元素的另一个属性的值,也可以是祖先元素的某个属性的值,甚至是格式化上下文的一个度量(比如包含块的宽度)。
具体来说:
- 宽度(width)、间距(maring/padding)支持百分比值,但默认的相对参考值是包含块的宽度;
- 高度(height)百分比的大小是相对其父级元素高的大小;
- 边框(border)不支持百分值;
- 边框圆角半径(border-radius)支持百分比值,但水平方向相对参考值是盒子的宽度,垂直方向相对参考值是盒子的高度;
- 文本大小(font-size)支持百分比值,但相对参考值是父元素的font-size的值;
- 盒阴影(box-shadow)和文本阴影(text-shadow)不支持百分比值;
首先,支持百分比单位的度量属性有其各自的参照基准,其次并非所有度量属性都支持百分比单位。所以我们需要另辟蹊径。
rem 适配方案
在 vw 方案出来之前,最被大众接受的就是使用 rem 进行适配的方案,因为 rem 满足上面说的,可以是一个全局性的基准单位。
rem(font size of the root element),在 CSS Values and Units Module Level 3中的定义就是, 根据网页的根元素来设置字体大小,和 em(font size of the element)的区别是,em 是根据其父元素的字体大小来设置,而 rem 是根据网页的跟元素(html)来设置字体大小。
flexible
基于此,淘宝早年推行的一套以 rem 为基准的适配方案:lib-flexible。其核心做法在于:
根据设备的 dpr 动态改写 标签,设置 viewport 的缩放给<html>元素添加data-dpr属性,并且动态改写data-dpr的值- 根据
document.documentElement.clientWidth动态修改<html>的 font-size ,页面其他元素使用 rem 作为长度单位进行布局,从而实现页面的等比缩放
关于头两点,其实现在的
lib-flexible库已经不这样做了,不再去缩放 Viewport,字体大小的设定也直接使用了 rem
hotcss
hotcss 不是一个库,也不是一个框架。它是一个移动端布局开发解决方案。使用 hotcss 可以让移动端布局开发更容易。本质的思想与 flexible 完全一致。
对于 rem 方案的一些总结
使用 flexible/hotcss 作为屏幕宽度适配解决方案,是存在一些问题的:
- 动态修改 Viewport 存在一定的风险的,譬如通过 Viewport 改变了页面的缩放之后,获取到的 innerWidth/innerHeight 也会随之发生变化,如果业务逻辑有获取此类高宽进行其他计算的,可能会导致意想不到的错误;
到今天,其实存在很多在 flexible 基础上演化而来的各种 rem 解决方案,有的不会对 Viewport 进行缩放处理,自行处理 1px 边框问题。
- flexible/hotcss 都并非纯 CSS 方案,需要引入一定的 Javascript 代码
- rem 的设计初衷并非是用于解决此类问题,用 rem 进行页面的宽度适配多少有一种 hack 的感觉
- 存在一定的兼容性问题,对于安卓 4.4 以下版本系统不支持 viewport 缩放(当然,flexible 处理 Android 系列时,始终认为其 dpr 为 1,没有进行 viewport 缩放)
vw 适配方案
严格来说,使用 rem 进行页面适配其实是一种 hack 手段,rem 单位的初衷本身并不是用来进行移动端页面宽度适配的。
到了今天,有了一种更好的替代方案,使用 vw 进行适配 。
百分比适配方案的核心需要一个全局通用的基准单位,rem 是不错,但是需要借助 Javascript 进行动态修改根元素的 font-size,而 vw/vh(vmax/vmin) 的出现则很好弥补 rem 需要 JS 辅助的缺点。
根据 CSS Values and Units Module Level 4:vw 等于初始包含块(html元素)宽度的1%,也就是
1vw等于window.innerWidth的数值的 1%1vh等于window.innerHeight的数值的 1%
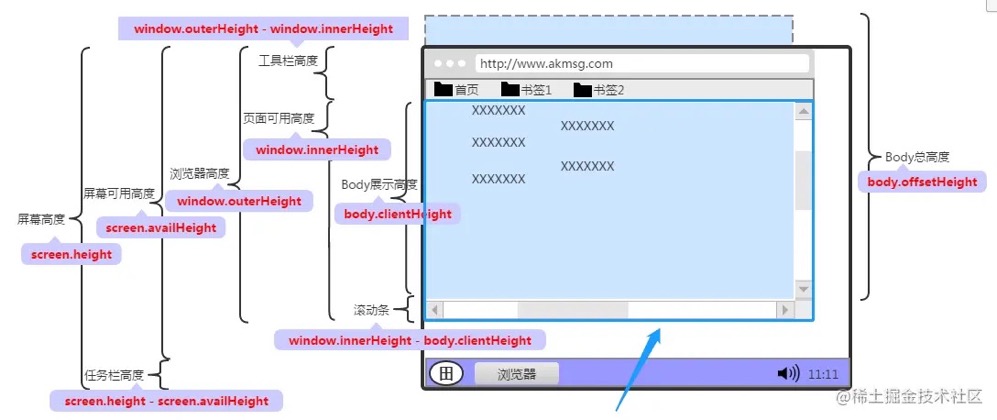
再以上面设计稿图的元素为例,那么,
- 元素的宽度为:209/375 = 55.73% = 55.73vw
- 元素的高度为:80/375 = 21.33% = 21.33vw
- 元素的上左右边距依次计算…
根据相关的测试,可以使用 vw 进行长度单位的有:
- 容器大小适配,可以使用 vw
- 文本大小的适配,可以使用 vw
- 大于 1px 的边框、圆角、阴影都可以使用 vw
- 内距和外距,可以使用 vw
简单的一个页面,看看效果,完全是等比例缩放的效果:
CodePen Demo(移动端打开):使用 vw 进行页面适配
自动转换插件
当我们使用 rem 作为长度单位的时,通常会有借助 Sass/Less 实现一个转换函数,像是这样:
// 假设设计稿的宽度是 375px,假设取设计稿宽度下 1rem = 100px
$baseFontSize: 100;
@function px2rem($px) {
@return $px / $baseFontSize * 1rem;
}
同理,在 vw 方案下,我们只需要去改写这个方法:
// 假设设计稿的宽度是 375px
@function px2vw($px) {
@return $px / 375 * 100vw;
}
当然,我们还可以借助一些插件包去实现这个自动转换,提高效率,譬如 postcss-px-to-viewport
vw polyfill
vw 现在毕竟还是存在兼容问题的,看看兼容性:
 其实已经覆盖了绝大部分设备,那么如果业务使用了且又真的出现了兼容问题,应该怎么处理呢?有两种方式可以进行降级处理:
其实已经覆盖了绝大部分设备,那么如果业务使用了且又真的出现了兼容问题,应该怎么处理呢?有两种方式可以进行降级处理:
- CSS Houdini:通过CSS Houdini针对vw做处理,调用CSS Typed OM Level1 提供的 CSSUnitValue API。
- CSS Polyfill:通过相应的Polyfill做相应的处理,目前针对于 vw 单位的 Polyfill 主要有:vminpoly、Viewport Units Buggyfill、vunits.js和 Modernizr
对于 vw 方案的一些总结
vw 确实看上去很不错,但是也是存在它的一些问题:
- 也没能很好的解决 1px 边框在高清屏下的显示问题,需要自行处理
- 由于 vw 方案是完全的等比缩放,在完全等比还原设计稿的同时带来的一个问题是无法很好的限定一个最大最小宽度值,由于 rem 方案是借助 Javascript 的,所以这一点 rem 比 vw 会更加的灵活
当然,两个方案现阶段其实都可以使用甚至一起搭配使用,更多详情可以读读:
参考文章:
杂七杂八
canvas drawImage 跨域问题:https://www.zhangxinxu.com/wordpress/2018/02/crossorigin-canvas-getimagedata-cors/
ES6
call、apply 和 bind
- call 的实现
Function.prototype.myCall = function(context) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
context = context || window;
context.fn = this;
var result;
var args = [];
for(var i = 1, len = arguments.length; i < len; i++) {
args.push('arguments[' + i + ']');
}
var result = eval('context.fn(' + args +')');
delete context.fn;
return result;
}
- apply 的实现
Function.prototype.myApply = function(context) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
context = context || window;
context.fn = this;
var result;
if (arguments[1]) {
result = context.fn(...arguments[1]);
} else {
result = context.fn();
}
delete context.fn;
return result;
}
- bind 特点:
- 函数调用,改变this ;
- 返回一个绑定this的函数;
- 接收多个参数 ;
- 支持柯里化形式传参 ,如 fn(1)(2);
实现 bind 时注意以下要点:
- 箭头函数的 this 永远指向它所在的作用域;
- 函数作为构造函数用 new 关键字调用时,不应该改变其 this 指向,因为 new绑定 的优先级高于 显示绑定 和 硬绑定;
// bind
if(!Function.prototype.bind) {
Function.prototype.bind = function(oThis) {
// 待绑定对象 不是函数,抛出错误
if (typeof this !== 'function') {
throw new TypeError("Function.prototype.bind - what is trying to be bound is not callable");
}
// 获取 绑定对象后的参数
var aArgs = Array.prototype.slice.call(arguments, 1),
// 待绑定对象 即待绑定函数
fToBind = this,
fNOP = function() {},
// 返回一个函数
fBound = function() {
//同样因为支持柯里化形式传参我们需要再次获取存储参数
var newArgs = Array.prototype.slice.call(arguments);
// 执行时的this指针时函数,指向原this;
// 否则指向新this对象
// this instanceof fNOP === true时,说明返回的fBound被当做new的构造函数调用
return fToBind.apply(
this instanceof fNOP ? this : oThis,
aArgs.concat(newArgs)
);
};
// 维护原型关系
// 箭头函数没有 prototype,箭头函数this永远指向它所在的作用域
if (this.prototype) {
// 当执行Function.prototype.bind()时, this为Function.prototype
// this.prototype(即Function.prototype.prototype)为undefined
fNOP.prototype = this.prototype;
}
// 下行的代码使fBound.prototype是fNOP的实例,因此
// 返回的fBound若作为new的构造函数,new生成的新对象作为this传入fBound,新对象的__proto__就是fNOP的实例
fBound.prototype = new fNOP();
return fBound;
}
}
Set、WeakSet、Map、WeakMap
- Set
- 成员不能重复
- 只有键值,没有键名,有点类似数组。
- 可以遍历,方法有add, delete, has
- 有 size、clear 方法
- WeakSet 和 Set 类似,是不重复的值的集合,但有两个区别:
- 成员都是对象
- 成员都是弱引用,随时可以消失。
弱引用,如果其他对象都不再引用该对象,gc直接回收, 因此不能遍历,方法有add, delete,has
WeakSet的一个用处,是储存DOM节点,而不用担心这些节点从文档移除时,会引发内存泄漏
- Map
- 本质上是键值对的集合,类似集合,但是“键”的范围不限于字符串,各种类型的值(包括对象)都可以当作键。
- 可以遍历,方法很多,可以跟各种数据格式转换
- 有 size()、set(key, value)、get(key)、has(key)、delete(key)、clear()
- 遍历方式: keys()、values()、entries()、forEach()
- WeakMap
- 直接受对象作为键名(null除外),不接受其他类型的值作为键名 键名所指向的对象,不计入垃圾回收机制 不能遍历,方法同get,set,has,delete
new 关键字
1. new 的作用
// 实现一个new
var Dog = function(name) {
this.name = name
}
Dog.prototype.bark = function() {
console.log('wangwang')
}
Dog.prototype.sayName = function() {
console.log('my name is ' + this.name)
}
let sanmao = new Dog('三毛')
sanmao.sayName();
sanmao.bark();
- 创建一个新对象obj;
- 把 obj 的 _proto_ 指向 Dog.prototype 实现继承;
- 执行构造函数,传递参数,改变this指向 :Dog.call(obj, …args);
- 若 Dog 函数的返回值是对象,则返回该对象,否则返回 obj;
- 最后把 obj 赋值给sanmao;
2. 实现
function _new(fn, ...arg) {
const obj = Object.create(fn.prototype);
const ret = fn.apply(obj, arg);
return ret instanceof Object ? ret : obj;
}
Promise
// 判断变量否为function
const isFunction = variable => typeof variable === 'function'
// 定义Promise的三种状态常量
const PENDING = 'PENDING'
const FULFILLED = 'FULFILLED'
const REJECTED = 'REJECTED'
class MyPromise {
constructor (handle) {
if (!isFunction(handle)) {
throw new Error('MyPromise must accept a function as a parameter')
}
// 添加状态
this._status = PENDING
// 添加状态
this._value = undefined
// 添加成功回调函数队列
this._fulfilledQueues = []
// 添加失败回调函数队列
this._rejectedQueues = []
// 执行handle
try {
handle(this._resolve.bind(this), this._reject.bind(this))
} catch (err) {
this._reject(err)
}
}
// 添加resovle时执行的函数
_resolve (val) {
const run = () => {
if (this._status !== PENDING) return
// 依次执行成功队列中的函数,并清空队列
const runFulfilled = (value) => {
let cb;
while (cb = this._fulfilledQueues.shift()) {
cb(value)
}
}
// 依次执行失败队列中的函数,并清空队列
const runRejected = (error) => {
let cb;
while (cb = this._rejectedQueues.shift()) {
cb(error)
}
}
/* 如果resolve的参数为Promise对象,则必须等待该Promise对象状态改变后,
当前Promsie的状态才会改变,且状态取决于参数Promsie对象的状态
*/
if (val instanceof MyPromise) {
val.then(value => {
this._value = value
this._status = FULFILLED
runFulfilled(value)
}, err => {
this._value = err
this._status = REJECTED
runRejected(err)
})
} else {
this._value = val
this._status = FULFILLED
runFulfilled(val)
}
}
// 为了支持同步的Promise,这里采用异步调用
setTimeout(run, 0)
}
// 添加reject时执行的函数
_reject (err) {
if (this._status !== PENDING) return
// 依次执行失败队列中的函数,并清空队列
const run = () => {
this._status = REJECTED
this._value = err
let cb;
while (cb = this._rejectedQueues.shift()) {
cb(err)
}
}
// 为了支持同步的Promise,这里采用异步调用
setTimeout(run, 0)
}
// 添加then方法
then (onFulfilled, onRejected) {
const { _value, _status } = this
// 返回一个新的Promise对象
return new MyPromise((onFulfilledNext, onRejectedNext) => {
// 封装一个成功时执行的函数
let fulfilled = value => {
try {
if (!isFunction(onFulfilled)) {
onFulfilledNext(value)
} else {
let res = onFulfilled(value);
if (res instanceof MyPromise) {
// 如果当前回调函数返回MyPromise对象,必须等待其状态改变后在执行下一个回调
res.then(onFulfilledNext, onRejectedNext)
} else {
//否则会将返回结果直接作为参数,传入下一个then的回调函数,并立即执行下一个then的回调函数
onFulfilledNext(res)
}
}
} catch (err) {
// 如果函数执行出错,新的Promise对象的状态为失败
onRejectedNext(err)
}
}
// 封装一个失败时执行的函数
let rejected = error => {
try {
if (!isFunction(onRejected)) {
onRejectedNext(error)
} else {
let res = onRejected(error);
if (res instanceof MyPromise) {
// 如果当前回调函数返回MyPromise对象,必须等待其状态改变后在执行下一个回调
res.then(onFulfilledNext, onRejectedNext)
} else {
//否则会将返回结果直接作为参数,传入下一个then的回调函数,并立即执行下一个then的回调函数
onFulfilledNext(res)
}
}
} catch (err) {
// 如果函数执行出错,新的Promise对象的状态为失败
onRejectedNext(err)
}
}
switch (_status) {
// 当状态为pending时,将then方法回调函数加入执行队列等待执行
case PENDING:
this._fulfilledQueues.push(fulfilled)
this._rejectedQueues.push(rejected)
break
// 当状态已经改变时,立即执行对应的回调函数
case FULFILLED:
fulfilled(_value)
break
case REJECTED:
rejected(_value)
break
}
})
}
// 添加catch方法
catch (onRejected) {
return this.then(undefined, onRejected)
}
// 添加静态resolve方法
static resolve (value) {
// 如果参数是MyPromise实例,直接返回这个实例
if (value instanceof MyPromise) return value
return new MyPromise(resolve => resolve(value))
}
// 添加静态reject方法
static reject (value) {
return new MyPromise((resolve ,reject) => reject(value))
}
// 添加静态all方法
static all (list) {
return new MyPromise((resolve, reject) => {
/**
* 返回值的集合
*/
let values = []
let count = 0
for (let [i, p] of list.entries()) {
// 数组参数如果不是MyPromise实例,先调用MyPromise.resolve
this.resolve(p).then(res => {
values[i] = res
count++
// 所有状态都变成fulfilled时返回的MyPromise状态就变成fulfilled
if (count === list.length) resolve(values)
}, err => {
// 有一个被rejected时返回的MyPromise状态就变成rejected
reject(err)
})
}
})
}
// 添加静态race方法
static race (list) {
return new MyPromise((resolve, reject) => {
for (let p of list) {
// 只要有一个实例率先改变状态,新的MyPromise的状态就跟着改变
this.resolve(p).then(res => {
resolve(res)
}, err => {
reject(err)
})
}
})
}
finally (cb) {
return this.then(
value => MyPromise.resolve(cb()).then(() => value),
reason => MyPromise.resolve(cb()).then(() => { throw reason })
);
}
}
prototype、__proto__
当谈到继承时,JavaScript 只有一种结构:对象。每个实例对象( object )都有一个私有属性(称之为 __proto__ )指向它的构造函数的原型对象( prototype )。该原型对象也有一个自己的原型对象( __proto__ ) ,层层向上直到一个对象的原型对象为 null。根据定义,null 没有原型,并作为这个原型链中的最后一个环节。
在 JavaScript 中,函数(function)是允许拥有属性的。所有的函数会有一个特别的属性 —— prototype 。
function doSomething(){}
console.log( doSomething.prototype );
// 和声明函数的方式无关,
// JavaScript 中的函数永远有一个默认原型属性。
var doSomething = function(){};
console.log( doSomething.prototype );
Flux、Redux、Mobx
Mobx
- MobX背后的哲学很简单:任何源自应用状态的东西都应该自动地获得。译成人话就是状态只要一变,其他用到状态的地方就都跟着自动变。
- MobX 更接近于面向对象编程,它把 state 包装成可观察的对象,这个对象会驱动各种改变;
对比 Mobx 和 Redux
- Redux 数据流流动很自然,可以充分利用时间回溯的特征,增强业务的可预测性;MobX 没有那么自然的数据流动,也没有时间回溯的能力,但是 View 更新很精确,粒度控制很细。
- Redux 通过引入一些中间件来处理副作用;MobX 没有中间件,副作用的处理比较自由,比如依靠 autorunAsync 之类的方法。
- Redux 的样板代码更多,看起来就像是我们要做顿饭,需要先买个调料盒装调料,再买个架子放刀叉。。。做一大堆准备工作,然后才开始炒菜;而 MobX 基本没啥多余代码,直接硬来,拿着炊具调料就开干,搞出来为止。
Redux
Redux 流程:
- 用户通过 View 发出 Action,Action 必须有一个 type 属性,代表 Action 的名称,其他可以设置一堆属性,作为参数供 State 变更时参考:
const aciton = {
type: 'ADD_TODO',
payload: 'Learn Redux'
};
store.dispatch(action);
- 然后 Store 自动调用 Reducer,并且传入两个参数:当前 State 和收到的 Action。 Reducer 会返回新的 State 。
let nextState = xxxReducer(previousState, action);
- State 一旦有变化,Store 就会调用监听函数,比如 React 的 setState 和 render 方法;
store.subscribe(listener);
- listener可以通过 store.getState() 得到当前状态。如果使用的是 React,这时可以触发重新渲染 View。
function listerner() {
let newState = store.getState();
component.setState(newState);
}
对比 Flux
- 和 Flux 比较一下:Flux 中 Store 是各自为战的,每个 Store 只对对应的 View 负责,每次更新都只通知对应的View:
- Redux 中各子 Reducer 都是由根 Reducer 统一管理的,每个子 Reducer 的变化都要经过根 Reducer 的整合:
简单来说,Redux有三大原则: Redux 单一数据源,Flux 的数据源可以是多个。 State 是只读的:Flux 的 State 可以随便改。 Redux 使用纯函数来执行修改:Flux 执行修改的不一定是纯函数。
参考资料
https://zhuanlan.zhihu.com/p/53599723
Mobx
mobx-react 工作原理:
-
observe组件会用 reactiveRender 重写render方法,reactiveRender 中的 reaction.track 建立与 observable 值的联系;
-
observe组件第一次渲染的时候,会创建Reaction,组件的render处于当前这个Reaction的上下文中,并通过track建立render中用到的observable建立关系;
-
当observable属性修改的时候,会触发onInvalidate方法,实际上就是组件的forceupdate,然后触发组件渲染,又回到了第一步
优化和最佳实践
- 使用transaction进行高级渲染性能优化;
- 延迟对象属性地解引用;
- 不要吝啬使用@observer,observer对性能的影响可以忽略不计,借助于精确的依赖分析,mobx可以得出组件对@observable变量(应用状态)的依赖图谱,对使用@observer进行标记的组件,实现精准的 shouldComponentUpdate 函数,保证组件100%无浪费渲染。
- 不要吝啬使用@action;action中封装了 transaction,对函数使用action修饰符后,无论函数中对 @observable 变量(应用状态)有多少次修改,都只会在函数执行完成后,触发一次对应的监听者;
observable
- createObservable(v, arg2, arg3)
- 第一个参数是 待监视对象,这个对象分为几种情况进行考虑:
- 对象, 如 {} , 判断方式 Object.getPrototypeOf(value) === Object.prototype || === null;
- 数组;Array.isArray
- ES6 的 Map,
- ES6 的 Set,
-
observable 上有对不同类型的监视对象的处理方法(这些方法定义在 observableFactories 对象上,再赋值到 observable 上);asCreateObservableOptions 处理 createObservable 的第二个参数,返回值赋值给 o;
-
如果 arg2 是未定义,返回默认的 defaultCreateObservableOptions;
// o
var defaultCreateObservableOptions = {
deep: true,
name: undefined,
defaultDecorator: undefined,
proxy: true
};
-
getDefaultDecoratorFromObjectOptions(o), deepDecorator = createDecoratorForEnhancer(deepEnhancer);
-
var base = extendObservable({}, undefined, undefined, o);asObservableObject();
-
var proxy = createDynamicObservableObject(base);
-
extendObservableObjectWithProperties(proxy, props, decorators, defaultDecorator);
-
asObservableObject
ObservableObjectAdministration(), addHiddenProp(), startBatch()
new Proxy(base, objectProxyTraps)
defaultDecorator decorator(target, key, descriptor, true)
Issue 笔记 链接
1. 写 React / Vue 项目时为什么要在列表组件中写 key,其作用是什么?
key是给每一个vnode的唯一id,可以依靠key,更准确, 更快的拿到oldVnode中对应的vnode节点。
-
更准确 因为带key就不是就地复用了,在sameNode函数 a.key === b.key对比中可以避免就地复用的情况。所以会更加准确。
-
更快 利用key的唯一性生成map对象来获取对应节点,比遍历方式更快。(这个观点,就是我最初的那个观点。从这个角度看,map会比遍历更快。)
2. 第 4 题:介绍下 Set、Map、WeakSet 和 WeakMap 的区别?
-
Set 成员不能重复, 可以遍历
-
WeakSet 成员不能重复,且只能是对象 不能遍历
-
Map 键值可以为任意类型 可以遍历
-
WeakMap 键值只能是对象 不能遍历
3. 常见异步笔试题
执行了流程: (macro)task->渲染->(macro)task->…
3.1 宏任务 macro task 主要包含:script(整体代码)、setTimeout、setInterval、I/O、UI交互事件、postMessage、MessageChannel、setImmediate(Node.js 环境);
3.2 微任务 micro task 主要包含:Promise.then、MutaionObserver、process.nextTick(Node.js 环境)
4.简单讲解一下 http2 的多路复用
HTTP/1 的问题:
- 每次请求都会建立一次HTTP连接,也就是我们常说的3次握手4次挥手,这个过程在一次请求过程中占用了相当长的时间;
- 队头阻塞问题,即使开启了 Keep-Alive,串行的文件传输,后面的请求只能等前一个返回后,才能发出。
- 服务器连接数过多。
HTTP/2 多路复用解决上述的两个性能问题:
- 在 HTTP/2 中,有两个非常重要的概念,分别是帧(frame)和流(stream)。
- 帧代表着最小的数据单位,每个帧会标识出该帧属于哪个流,流也就是多个帧组成的数据流。
- 多路复用,就是在一个 TCP 连接中可以存在多条流。换句话说,也就是可以发送多个请求,对端可以通过帧中的标识知道属于哪个请求。通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极大的提高传输性能。
5. React 中 setState 什么时候是同步的,什么时候是异步的?
如果是由React引发的事件处理(比如通过onClick引发的事件处理, 生命周期函数),调用setState不会同步更新this.state; 除此之外的setState调用会同步执行this.state。所谓“除此之外”,指的是绕过React通过addEventListener直接添加的事件处理函数,还有通过setTimeout/setInterval产生的异步调用。
6. 介绍下重绘和回流(Repaint & Reflow),以及如何进行优化
- 浏览器渲染机制
- 浏览器采用流式布局模型(Flow Based Layout)
- 浏览器会把HTML解析成DOM,把CSS解析成CSSOM,DOM和CSSOM合并就产生了渲染树(Render Tree)。
- 有了RenderTree,我们就知道了所有节点的样式,然后计算他们在页面上的大小和位置,最后把节点绘制到页面上。
- 由于浏览器使用流式布局,对Render Tree的计算通常只需要遍历一次就可以完成,但table及其内部元素除外,他们可能需要多次计算,通常要花3倍于同等元素的时间,这也是为什么要避免使用table布局的原因之一。
-
重绘 由于节点的几何属性发生改变或者由于样式发生改变而不会影响布局的,称为重绘;
-
回流 回流是布局或者几何属性需要改变就称为回流; 大部分的回流将导致页面的重新渲染。 回流必定会发生重绘,重绘不一定会引发回流。
-
减少回流和重绘
-
CSS:
- 使用 transform 替代 top;
- 使用 visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流(改变了布局);
- 避免使用table布局,可能很小的一个小改动会造成整个 table 的重新布局;
- 尽可能在DOM树的最末端改变class;
- 避免设置多层内联样式,CSS 选择符从右往左匹配查找,避免节点层级过多;
- 将动画效果应用到position属性为absolute或fixed的元素上,避免影响其他元素的布局,这样只是一个重绘,而不是回流;
- 同时,控制动画速度可以选择 requestAnimationFrame;
- 避免使用CSS表达式;
- 将频繁重绘或者回流的节点设置为图层,图层能够阻止该节点的渲染行为影响别的节点,例如will-change、video、iframe等标签,浏览器会自动将该节点变为图层;
- CSS3 硬件加速(GPU加速),使用css3硬件加速,可以让transform、opacity、filters这些动画不会引起回流重绘;
-
JavaScript:
- 避免频繁操作样式,最好一次性重写style属性,或者将样式列表定义为class并一次性更改class属性。
- 避免频繁操作DOM,创建一个documentFragment,在它上面应用所有DOM操作,最后再把它添加到文档中。
- 避免频繁读取会引发回流/重绘的属性,如果确实需要多次使用,就用一个变量缓存起来。
- 对具有复杂动画的元素使用绝对定位,使它脱离文档流,否则会引起父元素及后续元素频繁回流。
7. 介绍下 BFC 及其应用
-
BFC 就是块级格式上下文(Block Formatting Context,BFC),是页面盒模型布局中的一种 CSS 渲染模式,相当于一个独立的容器,里面的元素和外部的元素相互不影响。创建 BFC 的方式有:
- html 根元素;
- float 浮动;
- 绝对定位(position为absolute或者fixed);
- overflow 不为 visiable;
- display 为表格布局或者弹性布局;
-
BFC 主要的作用是:
- 清除浮动;
- 防止同一 BFC 容器中的相邻元素间的外边距重叠问题;
8. 怎么让一个 div 水平垂直居中
<div class="parent">
<div class="child"></div>
</div>
- flex 弹性布局
div.parent {
display: flex;
justify-content: center;
align-items: center;
}
- 绝对定位 + margin 或者 transform 偏移
div.parent {
position: relative;
}
div.child {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
/* 或者 */
div.child {
width: 50px;
height: 10px;
position: absolute;
top: 50%;
left: 50%;
margin-left: -25px;
margin-top: -5px;
}
/* 或 */
div.child {
width: 50px;
height: 10px;
position: absolute;
left: 0;
top: 0;
right: 0;
bottom: 0;
margin: auto;
}
- grid 布局
div.parent {
display: grid;
}
div.child {
justify-self: center;
align-self: center;
}
- 行高
div.parent {
font-size: 0;
text-align: center;
&::before {
content: "";
display: inline-block;
width: 0;
height: 100%;
vertical-align: middle;
}
}
div.child{
display: inline-block;
vertical-align: middle;
}
9.箭头函数与普通函数(function)的区别是什么?构造函数(function)可以使用 new 生成实例,那么箭头函数可以吗?为什么?
箭头函数是普通函数的简写,可以更优雅的定义一个函数,和普通函数相比,有以下几点差异:
- 1、函数体内的 this 对象,就是定义时所在的对象,而不是使用时所在的对象。
- 2、不可以使用 arguments 对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
- 3、不可以使用 yield 命令,因此箭头函数不能用作 Generator 函数。
- 4、不可以使用 new 命令,因为:
- 没有自己的 this,无法调用 call,apply。
- 没有 prototype 属性 ,而 new 命令在执行时需要将构造函数的 prototype 赋值给新的对象的 __proto__。
10. 介绍下 webpack 热更新原理,是如何做到在不刷新浏览器的前提下更新页面
- 当修改了一个或多个文件;
- 文件系统接收更改并通知webpack;
- webpack重新编译构建一个或多个模块,并通知 HMR Server 进行更新;
- HMR Server 使用webSocket通知 HMR runtime 需要更新,HMR runtime 通过HTTP请求更新jsonp;
- HMR运行时替换更新中的模块,如果确定这些模块无法更新,则触发整个页面刷新。
- 文件更改后,webpack对模块重新编译打包,并将打包后的代码保存到内存中;
- WDS 对文件变化监控,(这里监控的不是监控文件变化后打包,而是监控静态文件变化,通知浏览器 live reload);
- 通过 sockjs 建立的 websocket 长链接,将 webpack 编译状态和模块变化的hash值传递给浏览器,浏览器根据hash变化进行模块热替换;
- HotModuleReplacement.runtime 是客户端 HMR 的中枢,将接收到的新模块的hash值,通过 JsonpMainTemplate.runtime 向 server 端发送 Ajax 请求,服务端返回一个 json,该 json 包含了所有要更新的模块的 hash 值,获取到更新列表后,该模块再次通过 jsonp 请求,获取到最新的模块代码。
- HotModulePlugin 将会对新旧模块进行对比,决定是否更新模块,在决定更新模块后,检查模块之间的依赖关系,更新模块的同时更新模块间的依赖引用。
11. 介绍下 BFC、IFC、GFC 和 FFC
-
BFC(Block formatting contexts):块级格式上下文 页面上的一个隔离的渲染区域,那么他是如何产生的呢?可以触发BFC的元素有float、position、overflow、display:table-cell/ inline-block/table-caption ;BFC有什么作用呢?比如说实现多栏布局’
-
IFC(Inline formatting contexts):内联格式上下文 IFC的line box(线框)高度由其包含行内元素中最高的实际高度计算而来(不受到竖直方向的padding/margin影响)IFC中的line box一般左右都贴紧整个IFC,但是会因为float元素而扰乱。float元素会位于IFC与与line box之间,使得line box宽度缩短。 同个ifc下的多个line box高度会不同 IFC中时不可能有块级元素的,当插入块级元素时(如p中插入div)会产生两个匿名块与div分隔开,即产生两个IFC,每个IFC对外表现为块级元素,与div垂直排列。 那么IFC一般有什么用呢? 水平居中:当一个块要在环境中水平居中时,设置其为inline-block则会在外层产生IFC,通过text-align则可以使其水平居中。 垂直居中:创建一个IFC,用其中一个元素撑开父元素的高度,然后设置其vertical-align:middle,其他行内元素则可以在此父元素下垂直居中。
-
GFC(GrideLayout formatting contexts):网格布局格式化上下文 当为一个元素设置display值为grid的时候,此元素将会获得一个独立的渲染区域,我们可以通过在网格容器(grid container)上定义网格定义行(grid definition rows)和网格定义列(grid definition columns)属性各在网格项目(grid item)上定义网格行(grid row)和网格列(grid columns)为每一个网格项目(grid item)定义位置和空间。那么GFC有什么用呢,和table又有什么区别呢?首先同样是一个二维的表格,但GridLayout会有更加丰富的属性来控制行列,控制对齐以及更为精细的渲染语义和控制。
-
FFC(Flex formatting contexts):自适应格式上下文 display值为flex或者inline-flex的元素将会生成自适应容器(flex container),可惜这个牛逼的属性只有谷歌和火狐支持,不过在移动端也足够了,至少safari和chrome还是OK的,毕竟这俩在移动端才是王道。Flex Box 由伸缩容器和伸缩项目组成。通过设置元素的 display 属性为 flex 或 inline-flex 可以得到一个伸缩容器。设置为 flex 的容器被渲染为一个块级元素,而设置为 inline-flex 的容器则渲染为一个行内元素。伸缩容器中的每一个子元素都是一个伸缩项目。伸缩项目可以是任意数量的。伸缩容器外和伸缩项目内的一切元素都不受影响。简单地说,Flexbox 定义了伸缩容器内伸缩项目该如何布局。
12. 使用 JavaScript Proxy 实现简单的数据绑定
<body>
hello,world
<input type="text" id="model">
<p id="word"></p>
</body>
<script>
const model = document.getElementById("model")
const word = document.getElementById("word")
var obj= {};
const newObj = new Proxy(obj, {
get: function(target, key, receiver) {
console.log(`getting ${key}!`);
return Reflect.get(target, key, receiver);
},
set: function(target, key, value, receiver) {
console.log('setting',target, key, value, receiver);
if (key === "text") {
model.value = value;
word.innerHTML = value;
}
return Reflect.set(target, key, value, receiver);
}
});
model.addEventListener("keyup",function(e){
newObj.text = e.target.value
})
</script>
13. 永久性重定向(301)和临时性重定向(302)对 SEO 有什么影响
301重定向可促进搜索引擎优化效果 从搜索引擎优化角度出发,301重定向是网址重定向最为可行的一种办法。当网站的域名发生变更后,搜索引擎只对新网址进行索引,同时又会把旧地址下原有的外部链接如数转移到新地址下,从而不会让网站的排名因为网址变更而收到丝毫影响。同样,在使用301永久性重定向命令让多个域名指向网站主域时,亦不会对网站的排名产生任何负面影响。
302重定向可影响搜索引擎优化效果 迄今为止,能够对302重定向具备优异处理能力的只有Google。也就是说,在网站使用302重定向命令将其它域名指向主域时,只有Google会把其它域名的链接成绩计入主域,而其它搜索引擎只会把链接成绩向多个域名分摊,从而削弱主站的链接总量。既然作为网站排名关键因素之一的外链数量受到了影响,网站排名降低也是很自然的事情了。
理解301(永久重定向)是旧地址的资源已经被永久地删除了,搜索引擎在抓取新内容的同时也将旧的网站替换为重定向后的地址
302(临时重定向)旧地址的资源还在,这个重定向的只是临时从旧地址跳转到新地址,搜索引擎会抓取新的内容而保存旧的地址
14. 从URL输入到页面展现到底发生什么?
- DNS 解析:将域名解析成 IP 地址:
- DNS缓存 DNS存在着多级缓存,从离浏览器的距离排序的话,有以下几种: 浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。
- DNS负载均衡(DNS重定向) DNS负载均衡技术的实现原理是在DNS服务器中为同一个主机名配置多个IP地址,在应答DNS查询时, DNS服务器对每个查询将以DNS文件中主机记录的IP地址按顺序返回不同的解析结果,将客户端的访问 引导到不同的机器上去,使得不同的客户端访问不同的服务器,从而达到负载均衡的目的。
- TCP 连接:TCP 三次握手
- 发送 HTTP 请求
- 服务器处理请求并返回 HTTP 报文
- 浏览器解析渲染页面
- 断开连接:TCP 四次挥手
15.你要的 React 面试知识点,都在这了
16. 跨域
整个CORS通信过程,都是浏览器自动完成,不需要用户参与。对于开发者来说,CORS通信与同源的AJAX通信没有差别,代码完全一样。浏览器一旦发现AJAX请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加的请求,但用户不会有感觉。
因此,实现CORS通信的关键是服务器。只要服务器实现了CORS接口,就可以跨源通信。
- 简单请求
(1) 请求方法是以下三种方法之一:
- HEAD
- GET
- POST
(2)HTTP的头信息不超出以下几种字段:
- Accept
- Accept-Language
- Content-Type: 只限于三个值 application/x-www-form-urlencoded、multipart/form-data、text/plain
- Content-Language
- Last-Event-ID
服务端返回请求需有以下头部: (1)Access-Control-Allow-Origin: 必须; (2)Access-Control-Allow-Credentials: 该字段可选。它的值是一个布尔值,表示是否允许发送Cookie; (3)Access-Control-Expose-Headers: 该字段可选;
- 非简单请求
非简单请求是那种对服务器有特殊要求的请求,比如请求方法是PUT或DELETE,或者Content-Type字段的类型是application/json。
非简单请求的CORS请求,会在正式通信之前,增加一次HTTP查询请求,称为“预检“请求(preflight)。
浏览器先询问服务器,当前网页所在的域名是否在服务器的许可名单之中,以及可以使用哪些HTTP动词和头信息字段。只有得到肯定答复,浏览器才会发出正式的XMLHttpRequest请求,否则就报错。
JSONP:最大特点就是简单适用,老式浏览器全部支持,服务器改造非常小; 它的基本思想是,网页通过添加一个 <\script> 元素,向服务器请求JSON数据,这种做法不受同源政策限制;服务器收到请求后,将数据放在一个指定名字的回调函数里传回来。
function addScriptTag(src) {
var script = document.createElement('script');
script.setAttribute("type","text/javascript");
script.src = src;
document.body.appendChild(script);
}
window.onload = function () {
addScriptTag('http://example.com/ip?callback=foo');
}
function foo(data) {
console.log('Your public IP address is: ' + data.ip);
};
17. css 选择器优先级
从高到低: 1.id选择器(#myid)
2.类选择器(.myclassname)
3.标签选择器(div,h1,p)
4.子选择器(ul < li)
5.后代选择器(li a)
6.伪类选择(a:hover,li:nth-child)
18. http 状态码
301: 永久移动; 302: 临时移动; 303: 查看其它地址。与301类似。使用GET和POST请求查看; 304:未修改; 305: 使用代理; 307: 临时重定向。与302类似。使用GET请求重定向; 400: 客户端请求的语法错误,服务器无法理解; 401: 请求要求用户的身份认证; 403: 服务器理解请求客户端的请求,但是拒绝执行此请求; 404: 服务器无法根据客户端的请求找到资源(网页); 405: 客户端请求中的方法被禁止; 406: 服务器无法根据客户端请求的内容特性完成请求; 407: 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权; … 500:服务器内部错误,无法完成请求; 501: 服务器不支持请求的功能,无法完成请求; 502: 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应; 504: 充当网关或代理的服务器,未及时从远端服务器获取请求;
19. webpack 打包优化
- babel-loader 缓存;
- 抽离,一是webpack-dll-plugin,在首次构建时候就将这些静态依赖单独打包,后续只需要引用这个早就被打好的静态依赖包即可,有点类似“预编译”的概念;或者采用 Externals 的方式,我们将这些不需要打包的静态资源从构建逻辑中剔除出去,而使用 CDN 的方式,去引用它们;
- 在生产环境,避免使用 压缩,混淆等开发模式下不需要的功能;
- 选用合适的 devtool 配置(此选项控制是否生成,以及如何生成 source map),“eval” 具有最好的性能,但并不能帮助你转译代码。在大多数情况下,cheap-module-eval-source-map 是最好的选择;
20. webpack 的 loader 和 plugin 工作原理
- loader loader 用于对模块的源代码进行转换。loader 可以使你在 import 或“加载“模块时预处理文件。因此,loader 类似于其他构建工具中“任务(task)”,并提供了处理前端构建步骤的强大方法。loader 可以将文件从不同的语言(如 TypeScript)转换为 JavaScript,或将内联图像转换为 data URL。loader 甚至允许你直接在 JavaScript 模块中 import CSS文件!
- 编写 loader:
- loader 是导出为一个函数的 node 模块。该函数在 loader 转换资源的时候调用。给定的函数将调用 loader API,并通过 this 上下文访问;
- plugin
插件是 webpack 的支柱功能。webpack 自身也是构建于,你在 webpack 配置中用到的相同的插件系统之上!插件目的在于解决 loader 无法实现的其他事。
- webpack 插件由以下组成:
- 一个 JavaScript 命名函数。
- 在插件函数的 prototype 上定义一个 apply 方法。
- 指定一个绑定到 webpack 自身的事件钩子。
- 处理 webpack 内部实例的特定数据。
- 功能完成后调用 webpack 提供的回调。
// 一个 JavaScript 命名函数。
function MyExampleWebpackPlugin() {
};
// 在插件函数的 prototype 上定义一个 `apply` 方法。
MyExampleWebpackPlugin.prototype.apply = function(compiler) {
// 指定一个挂载到 webpack 自身的事件钩子。
compiler.plugin('webpacksEventHook', function(compilation /* 处理 webpack 内部实例的特定数据。*/, callback) {
console.log("This is an example plugin!!!");
// 功能完成后调用 webpack 提供的回调。
callback();
});
- compiler 对象代表了完整的 webpack 环境配置。这个对象在启动 webpack 时被一次性建立,并配置好所有可操作的设置,包括 options,loader 和 plugin。当在 webpack 环境中应用一个插件时,插件将收到此 compiler 对象的引用。可以使用它来访问 webpack 的主环境。
- compilation 对象代表了一次资源版本构建。当运行 webpack 开发环境中间件时,每当检测到一个文件变化,就会创建一个新的 compilation,从而生成一组新的编译资源。一个 compilation 对象表现了当前的模块资源、编译生成资源、变化的文件、以及被跟踪依赖的状态信息。compilation 对象也提供了很多关键时机的回调,以供插件做自定义处理时选择使用。
20. 把 list 专化成树形结构
const fn = arr => {
const res = [];
const map = arr.reduce((res, item) => ((res[item.id] = item), res), {});
for (const item of Object.values(map)) {
if (!item.pId) {
res.push(item);
} else {
const parent = map[item.pId];
parent.child = parent.child || [];
parent.child.push(item);
}
}
return res;
};
const arr = [
{ id: 1 },
{ id: 2, pId: 1 },
{ id: 3, pId: 2 },
{ id: 4 },
{ id: 3, pId: 2 },
{ id: 5, pId: 4 }
];
fn(arr);
21. JavaScript深入之4类常见内存泄漏及如何避免
- 垃圾回收算法
常用垃圾回收算法叫做标记清除 (Mark-and-sweep),算法由以下几步组成:
1、垃圾回收器创建了一个“roots”列表。roots 通常是代码中全局变量的引用。JavaScript 中,“window” 对象是一个全局变量,被当作 root 。window 对象总是存在,因此垃圾回收器可以检查它和它的所有子对象是否存在(即不是垃圾);
2、所有的 roots 被检查和标记为激活(即不是垃圾)。所有的子对象也被递归地检查。从 root 开始的所有对象如果是可达的,它就不被当作垃圾。
3、所有未被标记的内存会被当做垃圾,收集器现在可以释放内存,归还给操作系统了。
- 四种常见的JS内存泄漏
- 1、意外的全局变量
// 情况1: 未定义的变量会在全局对象创建一个新变量,如下
function foo(arg) {
bar = "this is a hidden global variable";
}
// 效果同下:
function foo(arg) {
window.bar = "this is an explicit global variable";
}
// 情况2: this 指向了全局对象(window)
function foo() {
this.variable = "potential accidental global";
}
解决方法: 在 JavaScript 文件头部加上 ‘use strict’,使用严格模式避免意外的全局变量,此时上例中的this指向undefined。如果必须使用全局变量存储大量数据时,确保用完以后把它设置为 null 或者重新定义。
-
2、被遗忘的计时器或回调函数
-
3、脱离 DOM 的引用
如果把DOM 存成字典(JSON 键值对)或者数组,此时,同样的 DOM 元素存在两个引用:一个在 DOM 树中,另一个在字典中。那么将来需要把两个引用都清除。
如果代码中保存了表格某一个
- 4、闭包
22. JavaScript常用八种继承方案
- 原型链继承 构造函数、原型和实例之间的关系:每个构造函数都有一个原型对象,原型对象都包含一个指向构造函数的指针,而实例都包含一个原型对象的指针。 继承的本质就是复制,即重写原型对象,代之以一个新类型的实例。 原型链方案存在的缺点:多个实例对引用类型的操作会被篡改。
function Parent() {
this.property = true;
}
Parent.prototype.getParentValue = function() {
return this.property;
}
function Child() {
this.subproperty = false;
}
// 这里是关键,创建SuperType的实例,并将该实例赋值给SubType.prototype
Child.prototype = new Parent();
Child.prototype.getChildValue = function() {
return this.subproperty;
}
var instance = new Child();
console.log(instance.getParentValue()); // true
- 借用构造函数继承 使用父类的构造函数来增强子类实例,等同于复制父类的实例给子类(不使用原型)
function SuperType(){
this.color=["red","green","blue"];
}
function SubType(){
//继承自SuperType
SuperType.call(this);
}
var instance1 = new SubType();
instance1.color.push("black");
alert(instance1.color);//"red,green,blue,black"
var instance2 = new SubType();
alert(instance2.color);//"red,green,blue"
核心代码是SuperType.call(this),创建子类实例时调用SuperType构造函数,于是SubType的每个实例都会将SuperType中的属性复制一份。 缺点:
- 只能继承父类的实例属性和方法,不能继承原型属性/方法
- 无法实现复用,每个子类都有父类实例函数的副本,影响性能
- 组合继承 组合上述两种方法就是组合继承。用原型链实现对原型属性和方法的继承,用借用构造函数技术来实现实例属性的继承。
function SuperType(name){
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function(){
alert(this.name);
};
function SubType(name, age){
// 继承属性
// 第二次调用SuperType()
SuperType.call(this, name);
this.age = age;
}
// 继承方法
// 构建原型链
// 第一次调用SuperType()
SubType.prototype = new SuperType();
// 重写SubType.prototype的constructor属性,指向自己的构造函数SubType
SubType.prototype.constructor = SubType;
SubType.prototype.sayAge = function(){
alert(this.age);
};
var instance1 = new SubType("Nicholas", 29);
instance1.colors.push("black");
alert(instance1.colors); //"red,blue,green,black"
instance1.sayName(); //"Nicholas";
instance1.sayAge(); //29
var instance2 = new SubType("Greg", 27);
alert(instance2.colors); //"red,blue,green"
instance2.sayName(); //"Greg";
instance2.sayAge(); //27
缺点:
- 第一次调用SuperType():给SubType.prototype写入两个属性name,color。
- 第二次调用SuperType():给instance1写入两个属性name,color。
- 原型式继承 利用一个空对象作为中介,将某个对象直接赋值给空对象构造函数的原型。
function object(obj){
function F(){}
F.prototype = obj;
return new F();
}
object()对传入其中的对象执行了一次浅复制,将构造函数F的原型直接指向传入的对象。
var person = {
name: "Nicholas",
friends: ["Shelby", "Court", "Van"]
};
var anotherPerson = object(person);
anotherPerson.name = "Greg";
anotherPerson.friends.push("Rob");
var yetAnotherPerson = object(person);
yetAnotherPerson.name = "Linda";
yetAnotherPerson.friends.push("Barbie");
alert(person.friends); //"Shelby,Court,Van,Rob,Barbie"
缺点:
- 原型链继承多个实例的引用类型属性指向相同,存在篡改的可能。
- 无法传递参数; 另外,ES5中存在Object.create()的方法,能够代替上面的object方法。
23. 给定两个数组,写一个方法来计算它们的交集
function intersection(x, y) {
var m = x.length;
var n = y.length;
// c 是 (m + 1) * (n + 1) 的二维数组
var c = [];
for (var i = 0; i <= m; i++) {
c[i] = [0];
}
for (var j = 0; j <= n; j++) {
c[0][j] = 0;
}
// 利用动态规划,自底向上求解
for(var i = 1; i <= m; i++) {
for(var j = 1; j <= n; j++) {
if (x[i-1] == y[j-1]) {
c[i][j] = c[i-1][j-1] + 1;
} else if (c[i - 1][j] >= c[i][j - 1]) {
c[i][j] = c[i - 1][j];
} else {
c[i][j] = c[i][j - 1];
}
}
}
print(c, x, y, m, n);
}
function print(c, x, y, i, j) {
if (i == 0 || j == 0) {
return;
}
if (x[i-1] == y[j-1]) {
print(c, x, y, i-1, j-1);
// console.log(x[i-1]);
intersectionArr.push(x[i - 1]);
} else if (c[i - 1][j] >= c[i][j - 1]) {
print(c, x, y, i - 1, j);
} else {
print(c, x, y, i, j - 1);
}
}
// 交集结果
var intersectionArr = [];
intersection([1, 2, 2, 1], [2, 2]);
// intersection([1, 2, 2, 1, 4, 5], [2, 2, 1, 3, 5]);
React
- key 相关;
https://reactjs.org/docs/lists-and-keys.html#keys https://medium.com/@robinpokorny/index-as-a-key-is-an-anti-pattern-e0349aece318 https://reactjs.org/docs/reconciliation.html#recursing-on-children
事件循环
- 关于微任务和宏任务在浏览器的执行顺序是这样的:
执行一只task(宏任务) 执行完micro-task队列 (微任务) 如此循环往复下去
常见的 task(宏任务) 比如:setTimeout、setInterval、script(整体代码)、 I/O 操作、UI 渲染等。 常见的 micro-task 比如: new Promise().then(回调)、MutationObserver(html5新特性) 等。
相关 api
- React.memo
- 类似于 React.PureComponent,用于函数式组建,相同的 props 渲染相同的内容
- 浅对比;shallowly compare complex objects in the props object;
- 第二个参数可以接受对比函数,自定义对比结果,返回布尔值,true表示重新选择,false表示使用之前的渲染结果
任务
-
call 、apply、bind 实现 -
class 实现 -
promise 实现 -
基本排序算法 -
nginx 设置
-
遇到的问题,解决方式,最有意义的项目
-
节流、防抖实现 -
webpack 常见问题: code splitting,hrm, tree shaking、dll、lazy-load
code splitting: https://www.webpackjs.com/plugins/split-chunks-plugin/
lazy-load: https://webpack.js.org/guides/lazy-loading/
-
图片懒加载 -
深拷贝 -
从输入URL到页面加载的过程 -
爬虫,seo
-
java 基本知识
-
React 相关 api
-
深度优先、 广度优先 -
react hooks
-
CSS3 动画相关属性
重要、重要、重要
-
mobx 原理, mobx 和 redux 区别
-
订阅-发布模式
-
react diff 算法
-
react 事件机制
-
树化列表 -
webpack 优化、loader/plugin工作原理
前端安全
一、XSS攻击 (跨站脚本攻击)
攻击方式
Cross Site Scripting,它允许恶意web用户将代码植入到提供给其它用户使用的页面中。
存储型、反射型、基于 DOM
1.1 防范手段
- 将前端输出数据都进行转义;
- 将cookie等敏感信息设置为httponly,禁止Javascript通过document.cookie获得;
二、 CSRF攻击(跨站请求伪造)
Cross-site request forgery,网站中的一些提交行为,被黑客利用,你在访问黑客的网站的时候,进行的操作,会被操作到其他网站上(如:你所使用的网络银行的网站)。
- 伪造请求不经过网站A
- 伪造请求的域名不是网站A
2.1防范手段
- 增加验证码
- cookies设置sameSite: 设置sameSite属性的值为strict,这样只有同源网站的请求才会带上cookies;
- 验证referer: 根据 HTTP 请求头的
referer来判断请求是否来自可信任网站; - 验证csrf token: 服务端随机生成token,保存在服务端session中,同时保存到客户端中,客户端发送请求时,把token带到HTTP请求头或参数中,服务端接收到请求,验证请求中的token与session中的是否一致;
三、HTTP劫持
大多数情况是运营商HTTP劫持,当我们使用HTTP请求请求一个网站页面的时候,网络运营商会在正常的数据流中插入精心设计的网络数据报文,让客户端(通常是浏览器)展示“错误”的数据,通常是一些弹窗,宣传性广告或者直接显示某网站的内容。
四、DNS劫持
通过劫持 DNS 服务器,通过某些手段取得某域名的解析记录控制权,进而修改此域名的解析结果,导致对该域名的访问由原IP地址转入到修改后的指定IP,其结果就是对特定的网址不能访问或访问的是假网址,从而实现窃取资料或者破坏原有正常服务的目的
五、控制台注入代码
六、同源策略
如果两个 URL 的协议、域名和端口都相同,我们就称这两个 URL 同源。
解决同源策略的方法:
- 跨域资源共享(CORS): 跨域资源在服务端设置允许跨域,就可以进行跨域访问控制,从而使跨域数据传输得以安全进行。
- 跨文档消息机制: 可以通过 window.postMessage 的 JavaScript 接口来和不同源的 DOM 进行通信。
- 内容安全策略(CSP):主要以白名单的形式配置可信任的内容来源,在网页中,能够使白名单中的内容正常执行(包含 JS,CSS,Image 等等),而非白名单的内容无法正常执行。
待深入
https://github.com/Advanced-Frontend/Daily-Interview-Question/issues?page=6&q=is%3Aissue+is%3Aopen
第 18 题:React 中 setState 什么时候是同步的,什么时候是异步的?
第 5 题 介绍下深度优先遍历和广度优先遍历,如何实现?
第 6 题 请分别用深度优先思想和广度优先思想实现一个拷贝函数?
进阶系列:
https://github.com/yygmind/blog/issues?page=1&q=is%3Aissue+is%3Aopen
算法:
https://juejin.im/post/5d5b307b5188253da24d3cd1